Reinforcement Learning assisted Loop Distribution for Locality and Vectorization
Shalini Jain, S. VenkataKeerthy, Rohit Aggarwal, Tharun Kumar Dangeti, Dibyendu Das, Ramakrishna Upadrasta
Published at LLVM-HPC 2022 Paper 
Loop distribution (loop fission) is a well known compiler optimization that splits the loop into multiple loops. Loop distribution can be seen as an enabler of various other optimizations with different goals, like, the parallelizability of the loop, the vectorizability of the loop, its locality characteristics.
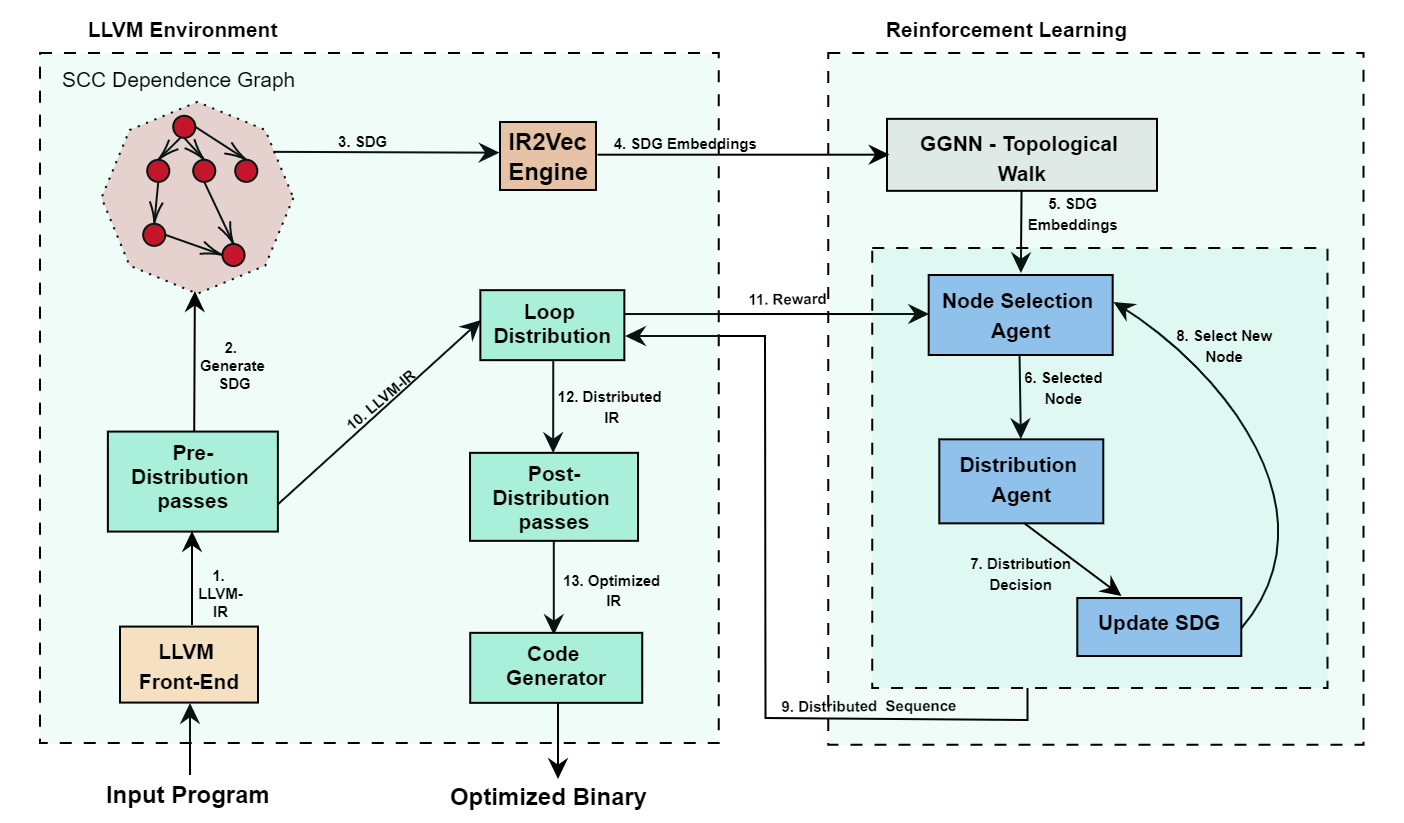
We present a Reinforcement Learning (RL) based approach to efficiently perform loop-distribution with the twin goals of optimizing for both vectorization as well as locality. Broadly, we generate the SCC Dependence Graph (SDG) for each loop of the program. Our RL model learns to predict the distribution order of the loop by performing topological walk of the graph. The reward to our model is computed using the instruction cost and number of cache misses of the loop. As the RL models need data for training purposes, we also propose a novel strategy to extend the training set by generating new loops.

For analyzing the dependences among the loop instructions we generate a reduced dependence graph (RDG) as explained earlier, but on the LLVM IR. In addition to the dependence edges, the constraint posed by the use-def relation of variables should also be respected. So, we account def-use edges along with the memory dependence edges.
The statements in the high level program are decomposed into multiple instructions in the LLVM-IR. Since dependence edges involve at least one write access, we primarily focus on store instructions in LLVM IR. Each node in the generated RDG consists of the instructions starting from the last definition of the variable up till its next definition. For this process, we obtain the program slices starting from a store instruction in a bottom-up fashion to represent an RDG node in LLVM IR. Program slices are obtained by recursively tracing the definitions of all the variables involved in an instruction, starting from the store node. This process results in the number of RDG nodes equal to the number of store LLVM-IR nodes in the loop.

Nodes in the SDG are created by merging the nodes in the RDG corresponding to each components of the SCC. The edges of the nodes that lie within the SCC are removed, and those edges across the SCC are retained. By construction, each SCC node of this SDG can form an independent loop and hence can be distributed.
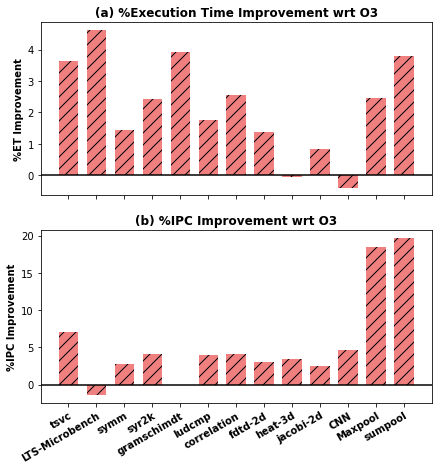
The improvements we achieved over O3 in terms of execution time and Instruction Per Cycle (IPC) for TSVC, LLVM-Test-Suite Microbenchmarks, PolyBench and PolyBench-NN benchmarks are shown below.
Artifacts
Artifacts are available in our GitHub page.
Funding
This research is funded by the Department of Electronics & Information Technology and the Ministry of Communications & Information Technology, Government of India. This work is partially supported by a Visvesvaraya PhD Scheme under the MEITY, GoI (PhD-MLA/04(02)/2015-16), an NSM research grant (MeitY/R&D/HPC/2(1)/2014), a Visvesvaraya Young Faculty Research Fellowship from MeitY, and a Google PhD Fellowship.