The Next 700 ML-Enabled Compiler Optimizations
S. VenkataKeerthy, Siddharth Jain, Umesh Kalvakuntla, Pranav Sai Gorantla, Rajiv Shailesh Chitale, Eugene Brevdo, Albert Cohen, Mircea Trofin, Ramakrishna Upadrasta
Published in CC 2024(arXiv) Slides Poster 
ML-Compiler-Bridge
There is a growing interest in enhancing compiler optimizations with ML models, yet interactions between compilers and ML frameworks remain challenging. Some optimizations require tightly coupled models and compiler internals, raising issues with modularity, performance and framework independence. Practical deployment and transparency for the end-user are also important concerns.
We propose MLCompiler-Bridge to enable ML model development within a traditional Python framework while making end-to-end integration with an optimizing compiler possible and efficient. We evaluate it on both research and production use cases, for training and inference, over several optimization problems, multiple compilers and its versions, and gym infrastructures.
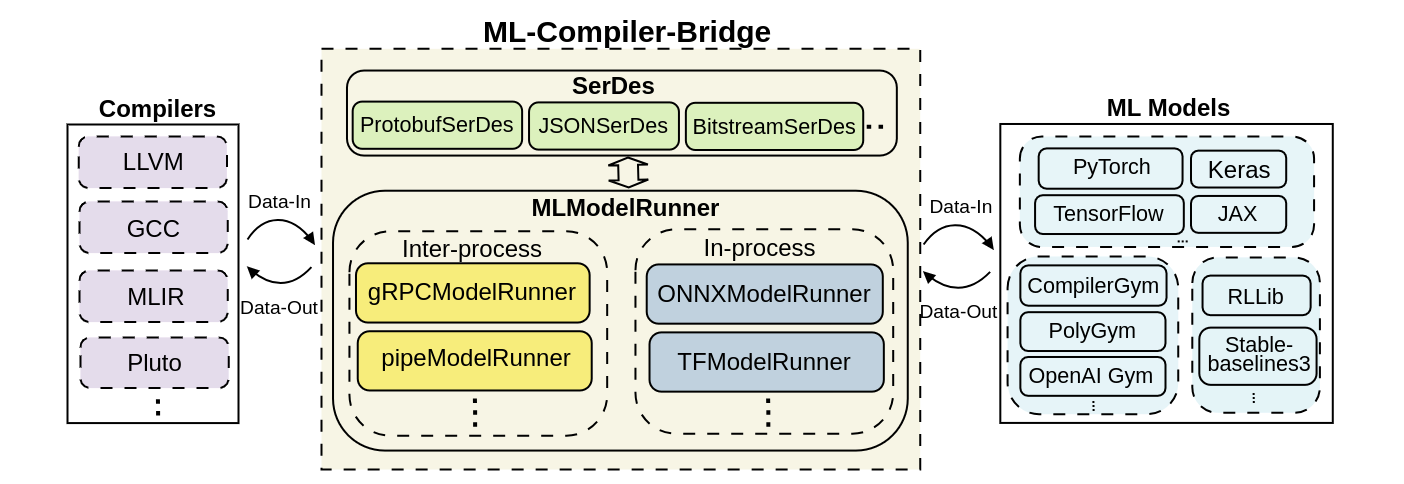
ML-Compiler-Bridge is compiler and ML-Framework independent library that can help in integrating compiler optimizations and ML models to aid in optimizations driven by ML approaches. Our library supports both a wide range of training and inference scenarios involving simple and multiple interleaved communications. ML-Compiler-Bridge can help in integrating the model deeper within the compiler easing out production related constraints.
Features
- Unified Framework: Comes with a suite of two inter-process and two in-process model runners and three serialization-deserialization mechanisms to support interleaved and non-interleaved communication between models and compiler.
- Multi-language Support: Exposes C++ and C APIs to interface model runners and serializers with the compilers and Python APIs to interface inter-process model runners with ML models.
- Compiler and ML-Framework Independence: Provides compiler and ML-Framework independent APIs, and supports easier integration with compilers like LLVM, MLIR, and Pluto and ML Frameworks like TensorFlow, PyTorch, JAX, etc.
- Deeper Integration: Enables deeper integration of ML models within the compiler in a framework-independent manner to support easier inference in case of ML driven compiler optimizations.
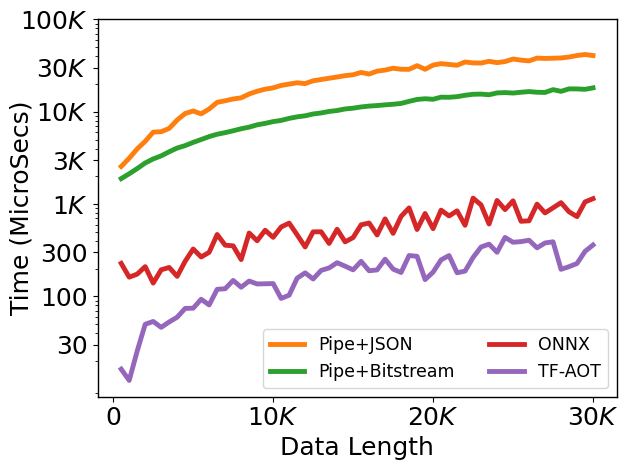
Currently, ML-Compiler-Bridge supports gRPC and pipes based inter-process communication via gRPCModelRunner and pipeModelRunner. The inter-process model runners mainly help in interfacing ML models and compilers during training process. Whereas, the in-process model runners are designed to provide an effective means of deployment. Such model runners use a compiled form of the model within the compiler, there by easing out the overheads due to inter-process communication scenarios. We currently support ONNX and TF AOT based model runners for inference.
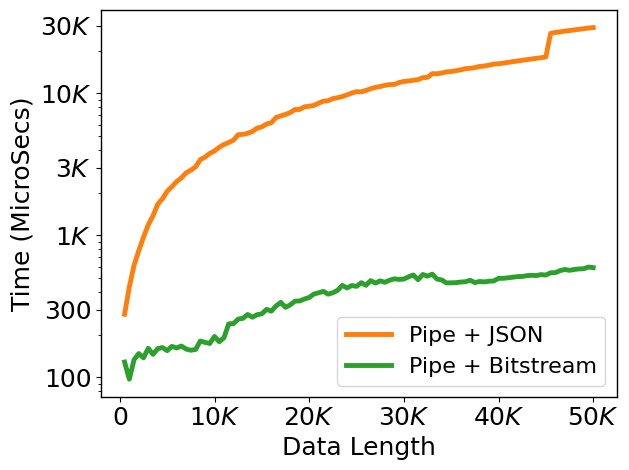
ML-Compiler-Bridge internally serializes and de-serializes data during inter-process communication in a seamless manner by using a SerDes module. Model runners interact with SerDes to (de-)serialize C++ native data to model-specific types and back. The choice of (de-)serialization depends on the optimization and ML model. We currently provide three options: bitstream, JSON, and Protobuf. They vary in terms of usage scenario, usage effort, and (de)serialization time.
ML-Compiler-Bridge is extendible; new model runners and serialization approaches can be added with a minimal effort.
Use Cases
ML-Compiler-Bridge can be readily integrated with LLVM, MLIR and Pluto compilers. For integration with Pluto, our C APIs can be used. Currently, our library is integrated with the following ML-based compiler optimizations in LLVM.
- POSET-RL – RL-based phase ordering for optimizing code-size and execution time.
- RL4ReAl – RL-based register allocator with splitting, coloring and spilling sub-tasks.
- Loop Distribution – RL-based Loop Distribution for vectorization and Locality.
- Inliner – RL-based inlining for code-size reduction.
These optimizations are available as a part of our ML-LLVM-Project.
Performance
Using ML-Compiler-Bridge can significantly improve the training and inference times.
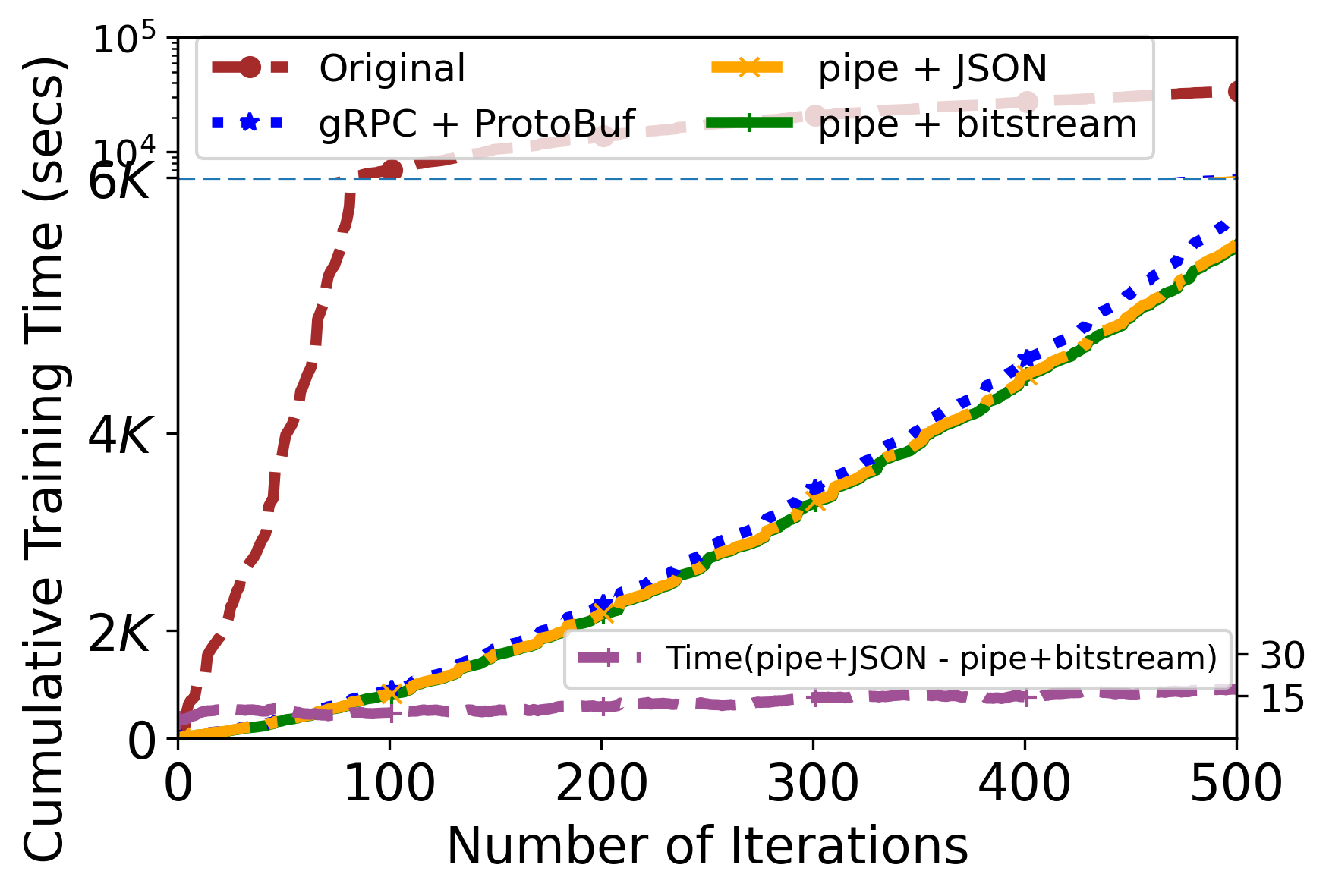
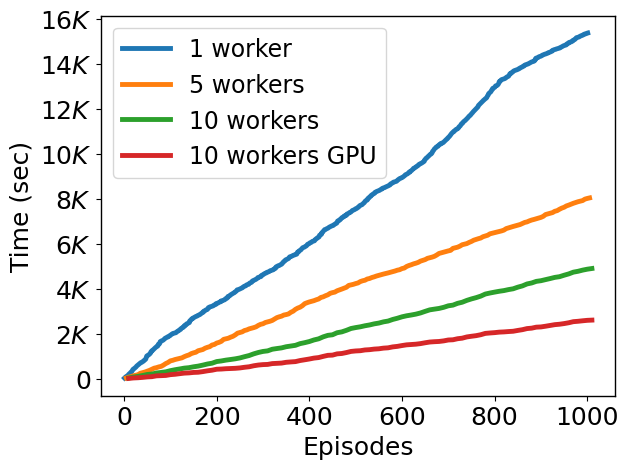
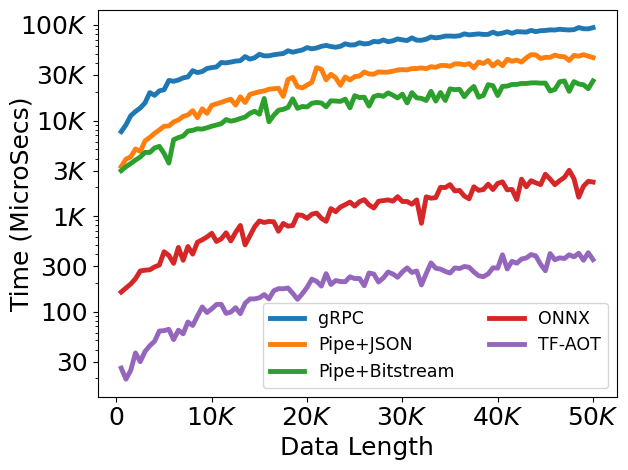
Artifacts
![]()
![]()
Code and other artifacts are available in our GitHub page.
The documentation and implementation specific details are available here.
Funding
This research is partially funded by a Google PhD fellowship, a PMRF fellowship, a research grant from Suzuki Motor Corporation, and a faculty research grant from AMD.