ML-LLVM-Tools: Towards Seamless Integration of Machine Learning in Compiler Optimizations
Siddharth Jain, S. VenkataKeerthy, Umesh Kalvakuntla, Albert Cohen, Ramakrishna Upadrasta
Technical Talk at EuroLLVM’23 (Slides)
With the growth in usage of Machine Learning (ML) to support compiler optimization decisions, there is a need for robust tools to support both training and inference. Such tools should be scalable and independent of the underlying model, and the ML framework upon which the model is built. We propose a unified infrastructure to aid ML based compiler optimizations in LLVM at each of training and inference stages by using: (1) LLVM-gRPC, a gRPC based framework to support training, (2) LLVM-InferenceEngine, a novel ONNX based infrastructure to support ML inference within LLVM. Our infrastructure allows seamless integration of both the approaches with ML based compiler optimization passes. When our LLVM-InferenceEngine is integrated with a recently proposed approach that uses Reinforcement Learning for performing Register Allocation, it results in a 12.5x speedup in compile time.
LLVM-gRPC: gRPC based framework to support Training
During the training phase, some optimizations necessitate a robust framework that allows to-and-fro communication between LLVM and the ML mode. RL4ReAl proposes a reinforcement learning approach to model register allocation in LLVM. This involves modeling the register allocation pass in LLVM as an RL environment that builds an interference graph and updates it upon splitting decisions by the model.
To support such complex cases, we propose LLVM-gRPC, where we integrate a gRPC framework with the LLVM toolchain; this is accomplished as an internal LLVM library, leveraging its modular structure. LLVM-gRPC exposes the components to facilitate communication with various libraries of LLVM by providing an option to either run a gRPC service, or to connect to an existing one.
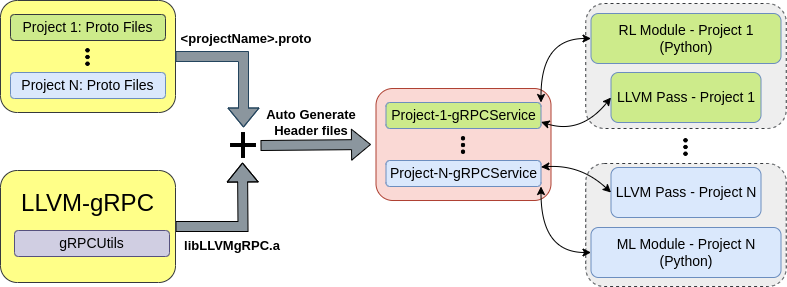
LLVM-InferenceEngine: ONNX based framework to support Inference
We propose to use ONNX - Open Neural Network Exchange which is an open format to represent machine learning models in the inference flow. Models built from various frameworks like TensorFlow, PyTorch, etc. can be represented in ONNX format in an interoperable manner. Additionally, ONNX supports a vast variety of hardware architecture ranging from edge devices to general purpose CPUs and GPUs. Once the model is trained in Python by using any of the commonly used ML frameworks, it can be exported into a common ONNX representation and can be imported into the C++ compiler via ONNX runtime.
We integrated the C++ ONNX Runtime with LLVM as a library - LLVMInferenceEngine, avoiding the inter-process communication overhead. Our library also exposes the necessary wrapper APIs to set the ONNX model path, query it with inputs, and obtain outputs without use of any RPC calls. Querying the model is as simple as calling a function exposed by the InferenceEngine. LLVM-InferenceEngine supports both ML and RL frameworks without other external dependencies in a seamless manner. To support RL models, it exposes various utility classes with necessary APIs. This includes classes for Environments and Agents 3tied together by a Driver class. Finally, LLVM-InferenceEngine also supports multiple agents for the optimizations modeled with multi-agent RL.
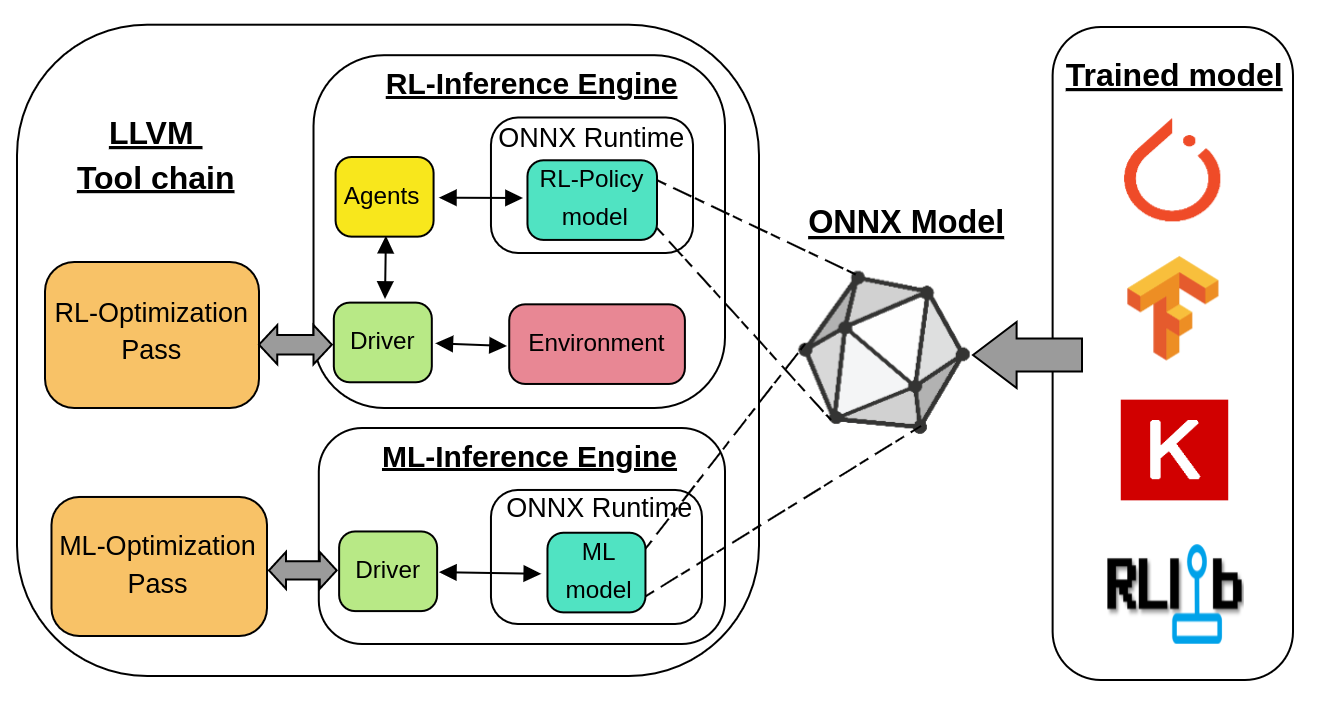
This library can be linked with the LLVM pass that performs ML based optimization. Once the model is trained, the model can be exported to ONNX format and imported into the LLVM pass via LLVM-InferenceEngine which can then query the model with appropriate inputs during inference (compilation). In case of pass using RL model, the user has to override the relevantclasses exposed by the library to make use of Environment and Agents.
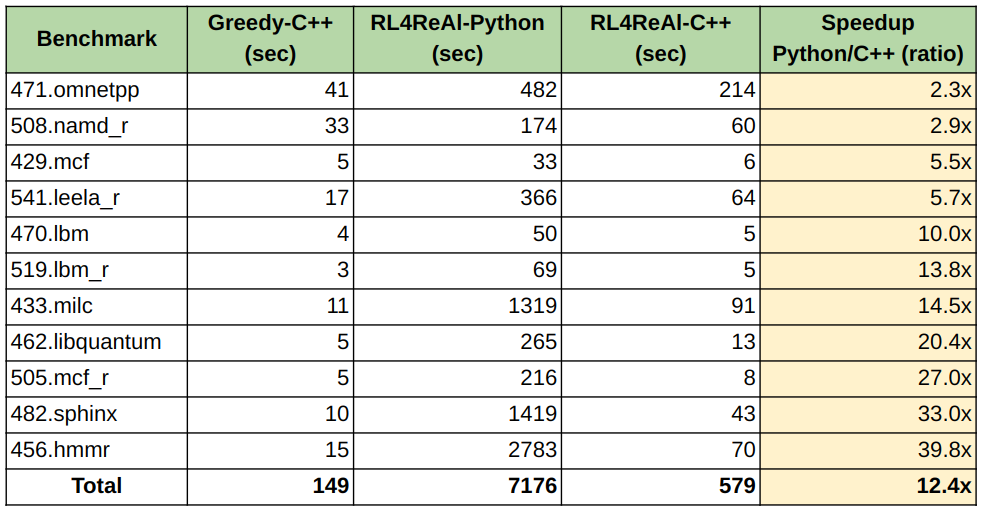
Results
We integrated our LLVM-InferenceEngine with RL4ReAl, and compare the obtained compile times with that of LLVM-gRPC. We observe significant compile-time speedups ranging from 2x and 40x on compiling benchmarks from SPEC CPU 2006 and 2017. Detailed results are shown in Table below. In total, we observe 12.4x speedup in comparison to the benchmarks compiled with LLVM-gRPC, making LLVM-InferenceEngine a promising choice.