PolyUFC: Polyhedral Compilation Meets Roofline Analysis for Uncore Frequency Capping
Nilesh Rajendra Shah, M V V S Manoj Kumar, Dhairya Baxi, and Ramakrishna Upadrasta
Published in CGO’26
Overview
Modern server processors contain a large uncore subsystem—including the last-level cache (LLC), memory controllers, and on-chip interconnects—which constitutes a significant fraction of total processor power. While contemporary compilers aggressively optimize computation on CPU cores, they largely overlook opportunities for compiler-driven management of the uncore subsystem. As a result, modern processors frequently operate with over-provisioned uncore frequencies, leading to unnecessary power consumption without meaningful performance benefits.

PolyUFC addresses this gap by introducing a compiler-driven framework for uncore frequency capping that combines:
- Polyhedral compilation
- Roofline-based performance and power modeling
- Static cache and operational intensity analysis
The framework is implemented within the MLIR compiler infrastructure, enabling architecture-aware energy optimization for both affine programs and modern machine learning kernels.
PolyUFC automatically derives optimal uncore frequency caps by statically characterizing program behavior and embedding frequency control into Pluto-optimized code generated by Polygeist.
Across a diverse set of workloads drawn from vision models, NLP workloads, and the PolyBench scientific benchmark suite, PolyUFC achieves:
- Up to 42% improvement in Energy Delay Product (EDP) for compute-bound kernels
- Up to 54% improvement in EDP for bandwidth-bound kernels
These improvements are validated on real Intel microarchitectures, demonstrating that compiler-guided uncore frequency management can significantly improve energy efficiency without sacrificing performance.
Key Contributions
PolyUFC introduces a set of techniques that bridge polyhedral compilation and architecture-aware energy optimization.
Compiler-driven uncore frequency capping.
PolyUFC is the first MLIR-based compilation flow that automatically determines energy-efficient uncore frequency caps using static program analysis and architecture-aware modeling.
Static estimation of Operational Intensity (OI).
We develop a polyhedral-analysis-based method for estimating operational intensity directly from affine programs, eliminating the need for expensive runtime profiling or hardware counter instrumentation.
POLYUFC-CM: Static cache modeling for set-associative caches.
PolyUFC introduces a scalable cache model that approximates reuse distances and conflict/capacity misses in tiled affine programs, enabling compile-time estimation of DRAM traffic.
Roofline-aware performance and power modeling.
PolyUFC integrates performance and power roofline models into a parametric framework that estimates execution time, bandwidth, and power consumption as functions of program characteristics and uncore frequency.
Phase-aware frequency optimization across MLIR dialects.
PolyUFC performs fine-grained characterization at the affine IR level while applying frequency caps at loop-nest or linalg operation boundaries, enabling efficient optimization of both scientific kernels and deep learning workloads.
PolyUFC Compilation Framework
PolyUFC integrates static program analysis, architecture-aware modeling, and compiler transformations to determine optimal uncore frequency configurations.
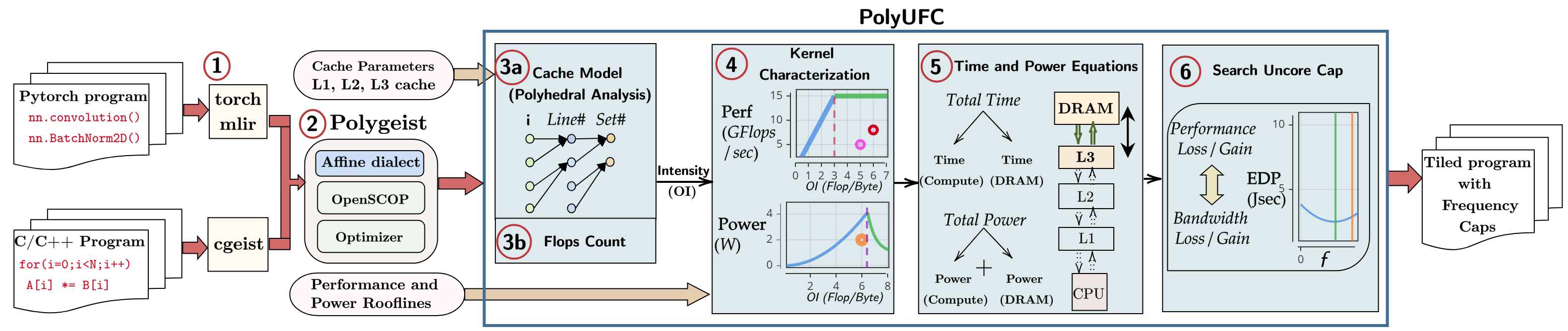
The compilation pipeline operates as follows:
- Program lowering to MLIR from C/C++ or PyTorch frontends
- Affine dialect generation and polyhedral optimization using Pluto
- Static cache analysis and operational intensity estimation
- Roofline-based performance and power characterization
- Search for optimal uncore frequency caps
- Code generation with frequency control instrumentation
By combining static analysis with architectural modeling, PolyUFC enables compile-time identification of energy-efficient execution configurations, avoiding the overheads associated with runtime profiling or dynamic power management heuristics.
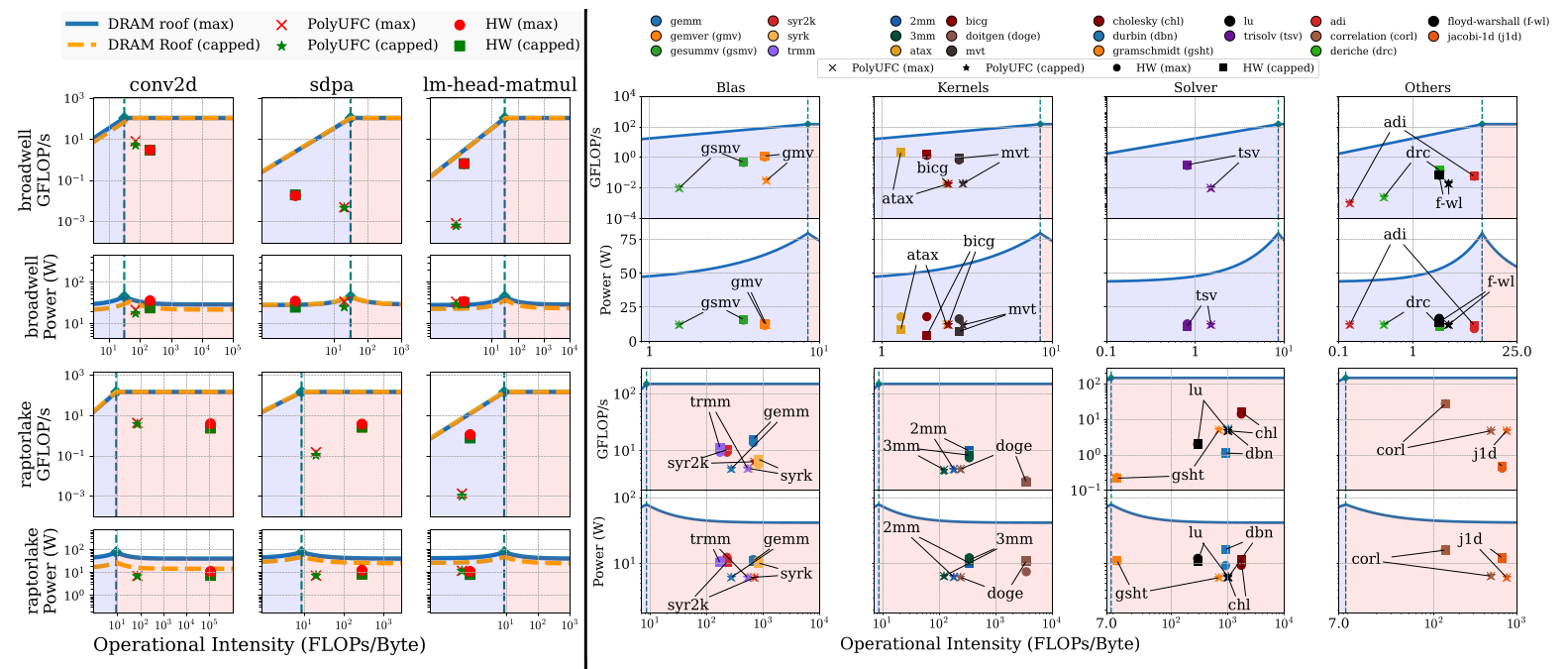
Roofline-Based Program Characterization
PolyUFC characterizes program behavior using Operational Intensity (OI), defined as:
$OI = \frac{\text{Floating Point Operations}}{\text{Bytes transferred between LLC and DRAM}}$
Operational intensity provides a principled way to reason about the compute–memory balance of an application. By comparing OI against the architecture’s machine balance derived from the roofline model, programs can be classified into two regimes:
Compute-Bound (CB)
$OI \geq \text{Machine Balance}$
These kernels are limited by compute throughput and exhibit little sensitivity to memory bandwidth.
Bandwidth-Bound (BB)
$OI < \text{Machine Balance}$
These kernels are limited by memory bandwidth and benefit from higher uncore frequencies.
This classification allows PolyUFC to determine whether reducing or increasing the uncore frequency will improve energy efficiency while maintaining performance.
Parametric Performance and Power Modeling
PolyUFC derives architecture-aware analytical models that estimate performance, bandwidth, and power consumption as functions of:
- Uncore frequency $f_c$
- Operational intensity $I$
Compute time depends on total floating-point operations and processor throughput, while memory transfer time is derived from cache miss analysis and DRAM latency modeling.
Performance Characterization
Performance and bandwidth estimation assumes no overlap between compute and memory phases. The total execution time is therefore decomposed into compute time and memory transfer time. Compute time is derived from static FLOP counts and processor throughput, while memory time is estimated using cache analysis and frequency-aware latency modeling.
Performance/Bandwidth Estimation
Total execution time with frequency cap as a parameter:
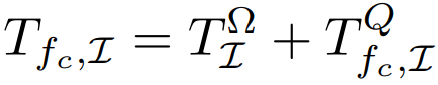
where:
- $T_{\Omega}$ represents compute time
- $T_Q$ represents memory transfer time
Compute performance:
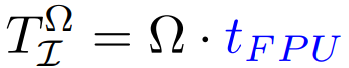
Data movement latency with uncore frequency cap:
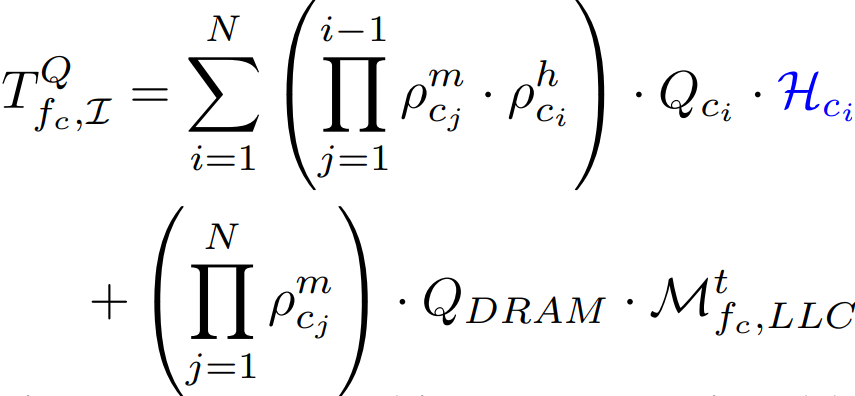
Total Compute Performance:
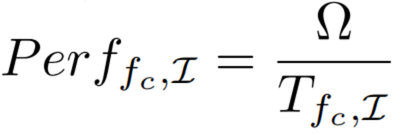
Total LLC Bandwidth:
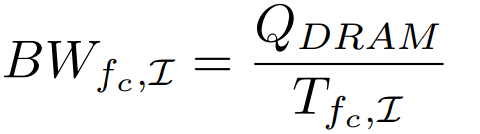
Uncore Power Characterization and Estimation
Total power estimation includes contributions from both core and uncore subsystems, with core power modeled at the maximum core frequency.
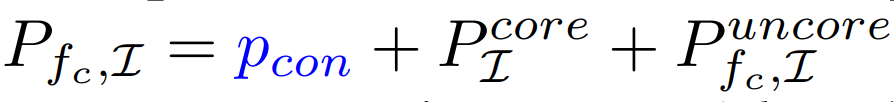
Peak power as a function of scaling frequency:
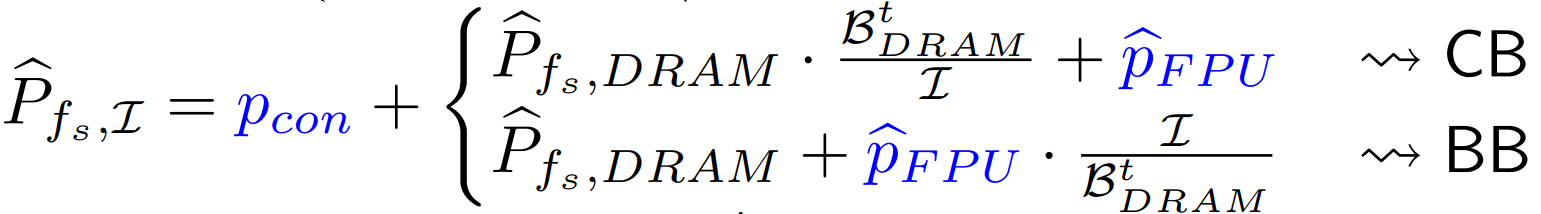
Peak DRAM power modeled as an affine function:
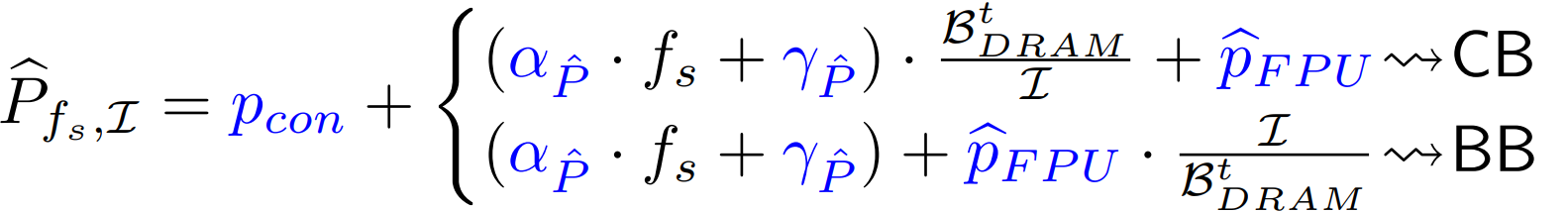
Total power with frequency capping:
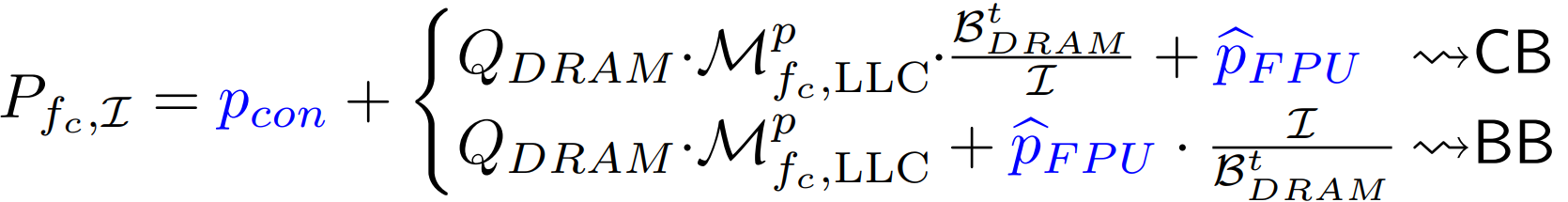
Miss-penalty power modeling:
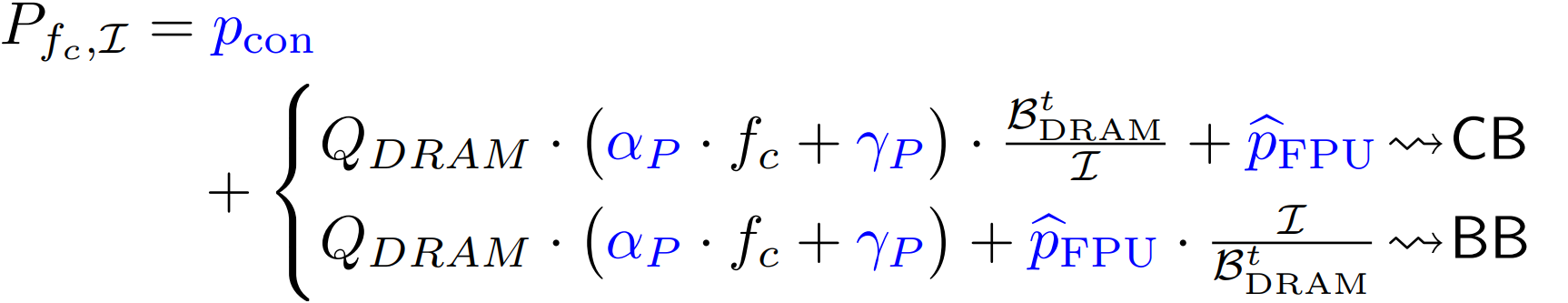
Energy per loop nest:
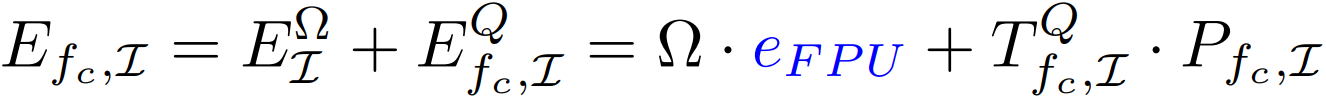
POLYUFC-CM: Static Cache Analysis
PolyUFC introduces POLYUFC-CM, a scalable static cache analysis framework designed for tiled affine programs.
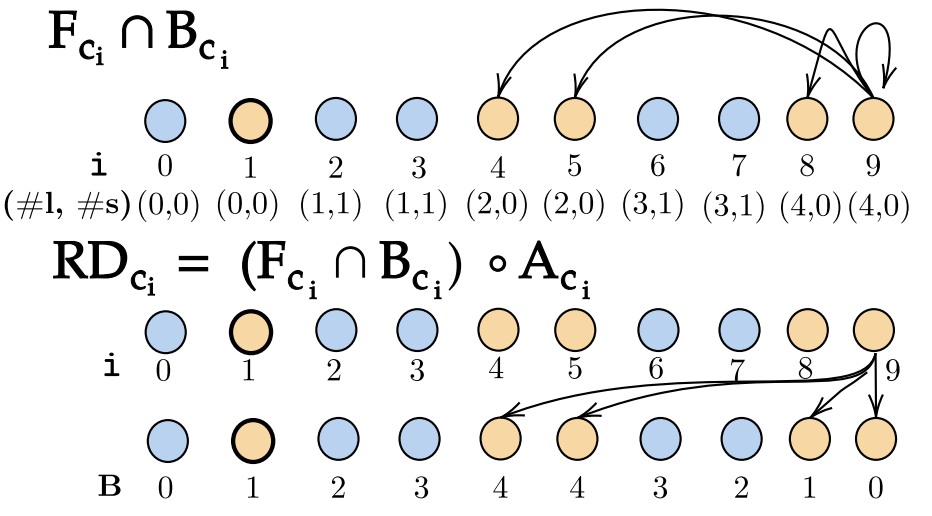
The model approximates the behavior of set-associative caches by treating each cache set as a fully associative structure and computing reuse pairs to estimate reuse distances.
This analysis enables the identification of:
- Compulsory misses
- Capacity misses
- Conflict misses
To model parallel execution, the framework approximates shared working-set behavior by distributing sequential miss counts across the number of OpenMP threads. While approximate, this method provides an effective and scalable mechanism for estimating memory traffic in multi-threaded workloads.
Cache Modeling Example

Phase-Aware Frequency Capping
PolyUFC enables phase-aware uncore frequency control across program execution.
Program characterization is performed at the affine IR level, enabling statement-level analysis of compute and memory behavior. Frequency caps are then applied at:
- Loop-nest granularity for affine programs
- linalg operation granularity for machine learning workloads
This design strikes a balance between optimization precision and runtime overhead.
Frequency Selection Strategy
For each program phase:
- Compute-bound phases: choose to decrease uncore frequency cap
- Bandwidth-bound phases: choose to increase uncore frequency cap
This ensures that compute-intensive kernels avoid unnecessary power consumption while memory-intensive kernels maintain sufficient bandwidth.
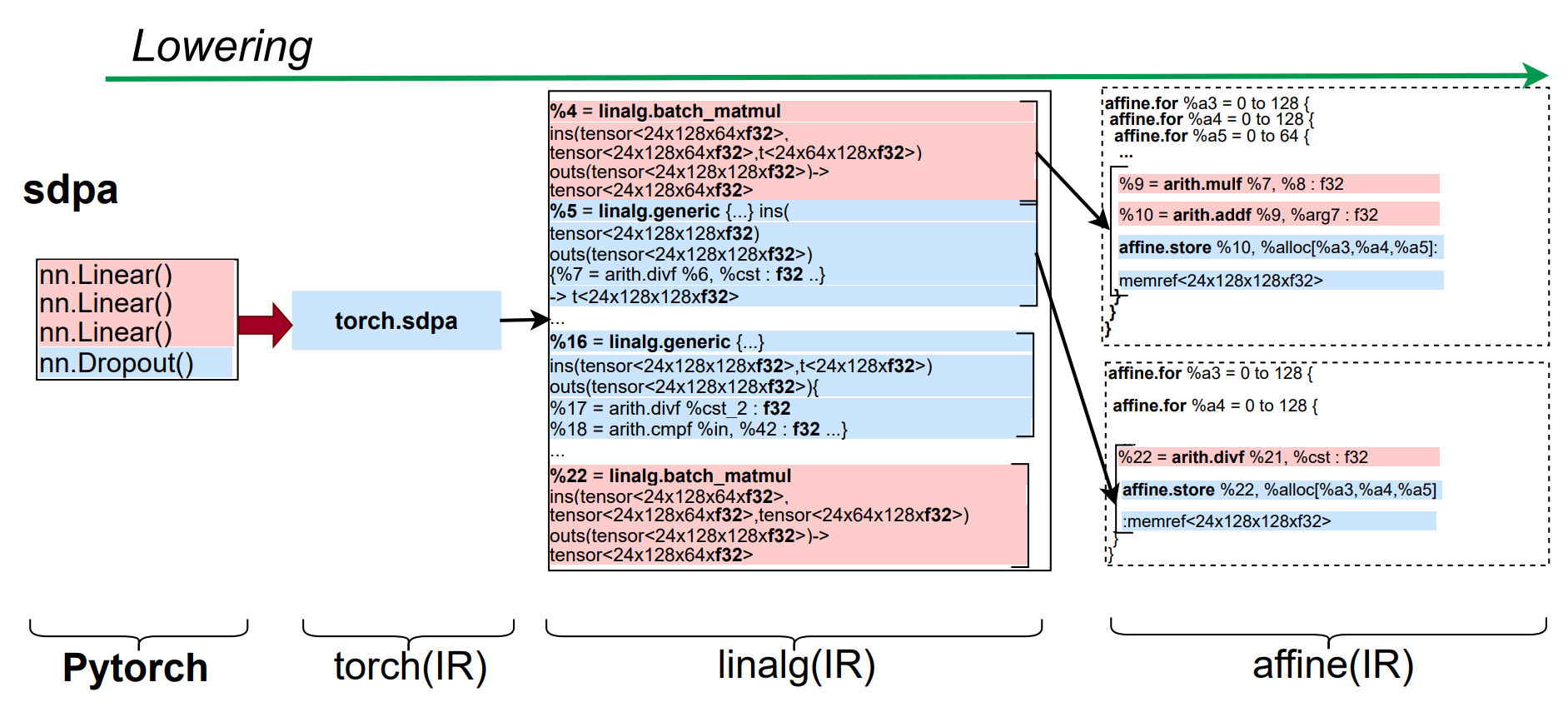
Phase Changes in ML Workloads
The figure below illustrates phase transitions across compiler IR levels for Scaled Dot Product Attention (SDPA) in BERT.
Experimental Evaluation
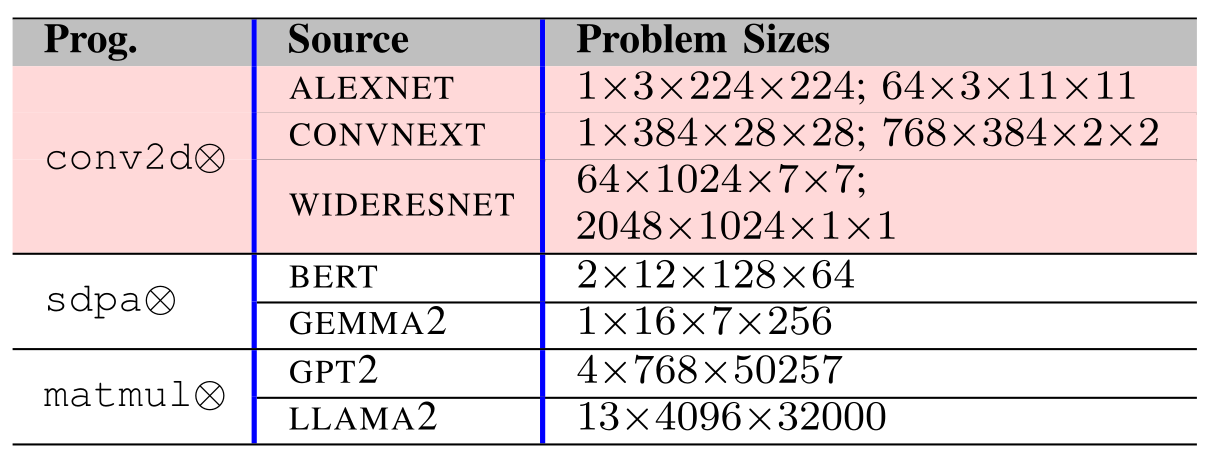
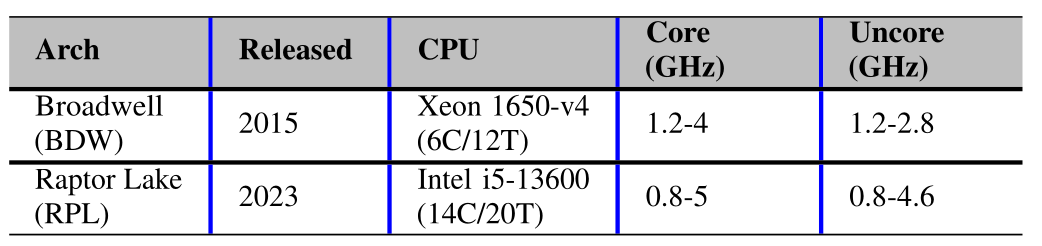
PolyUFC was evaluated on two modern Intel microarchitectures using workloads from both machine learning models and scientific computing benchmarks.
- Vision and NLP workloads (BERT, GPT, LLaMA, AlexNet, ConvNeXt)
- Scientific kernels from the PolyBench benchmark suite
Roofline Characterization
Static roofline characterization of ML kernels and PolyBench workloads:
Energy, Performance and EDP Improvements
PolyUFC delivers significant improvements in energy efficiency:
- Up to 42% EDP improvement for compute-bound kernels
- Up to 54% EDP improvement for bandwidth-bound kernels
- Accurate static characterization of program behavior
- Minimal runtime overhead for frequency switching
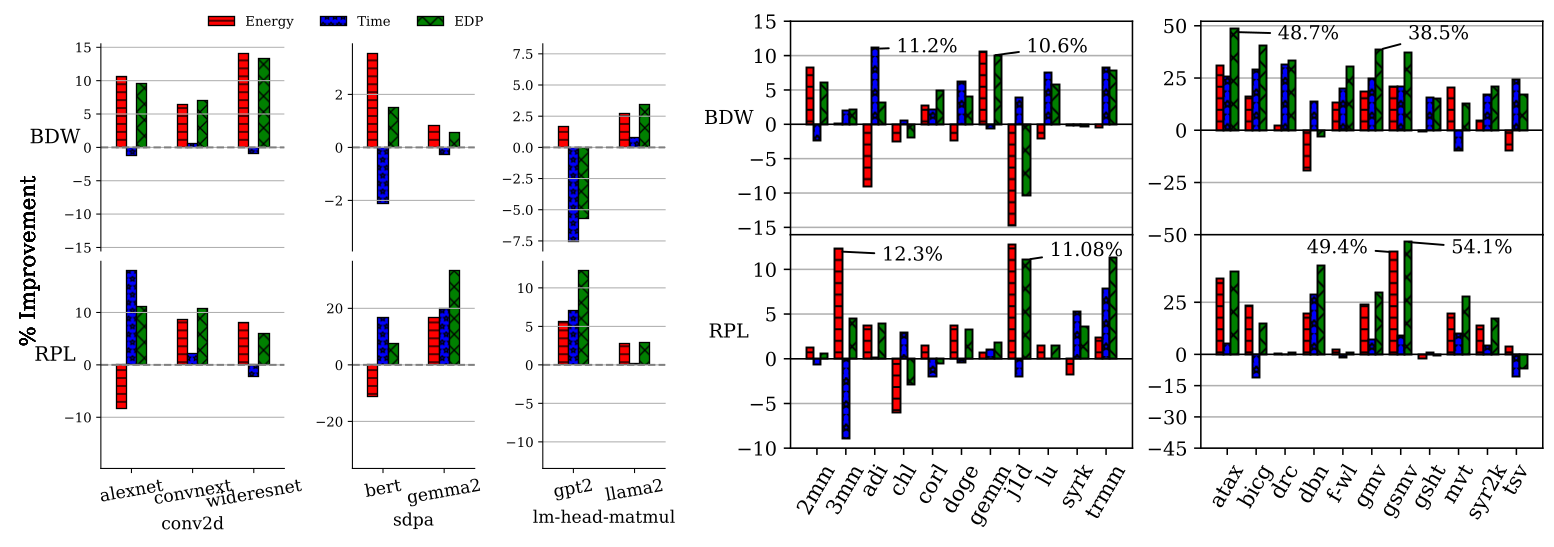
These results demonstrate that compiler-guided uncore frequency optimization provides a powerful new dimension for energy-efficient compilation.
Additional Resources
Supplementary material and additional results are available here:
Funding
This work is supported by the Prime Minister’s Research Fellowship (PMRF) programme, Government of India, with additional support from faculty grants provided by AMD and Qualcomm.