PolyDL: Polyhedral Optimizations for Creation of High Performance DL primitives
Sanket Tavarageri, Alexander Heinecke, Sasikanth Avancha, Gagandeep Goyal, Ramakrishna Upadrasta, Bharat Kaul
Published in ACM TACO (pre-print) (Talks: HiPEAC’21) 
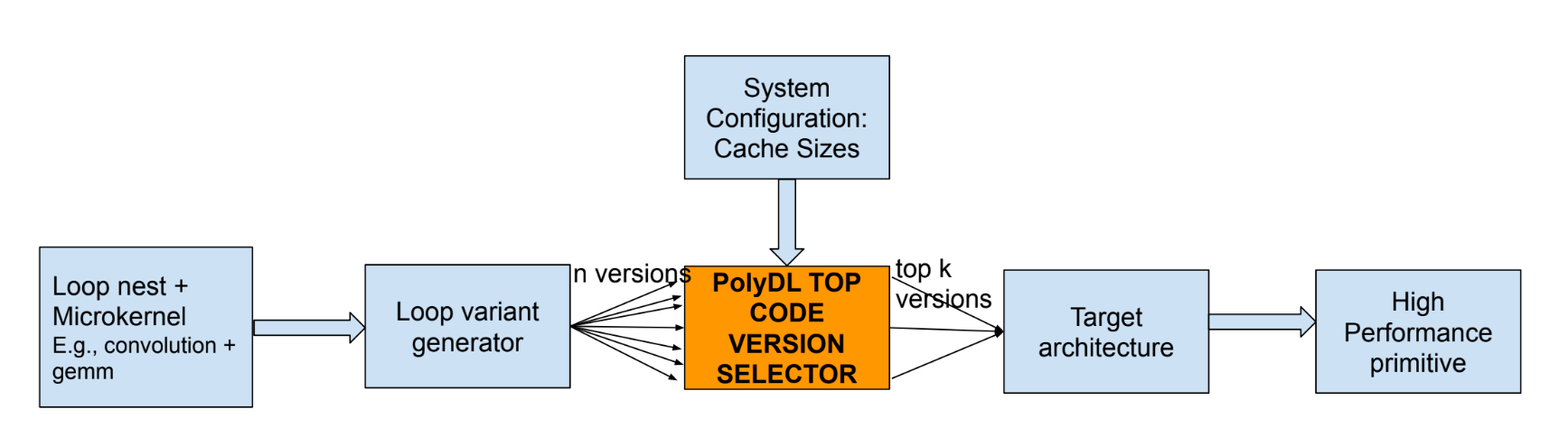
PolyDL framework optimizes DL codes on CPUs following a two-step approach. Outer loop tuning with novel reuse algorithm in Polyhedral Compilation. For the inner loop, the expertly coded microkernels are used for effective vectorization. The performance of the generated code by the PolyDL system is comparable to the (Intel) oneDNN library. PolyDL system eases the development of high performance for DL workloads and is faster than autotuning systems.
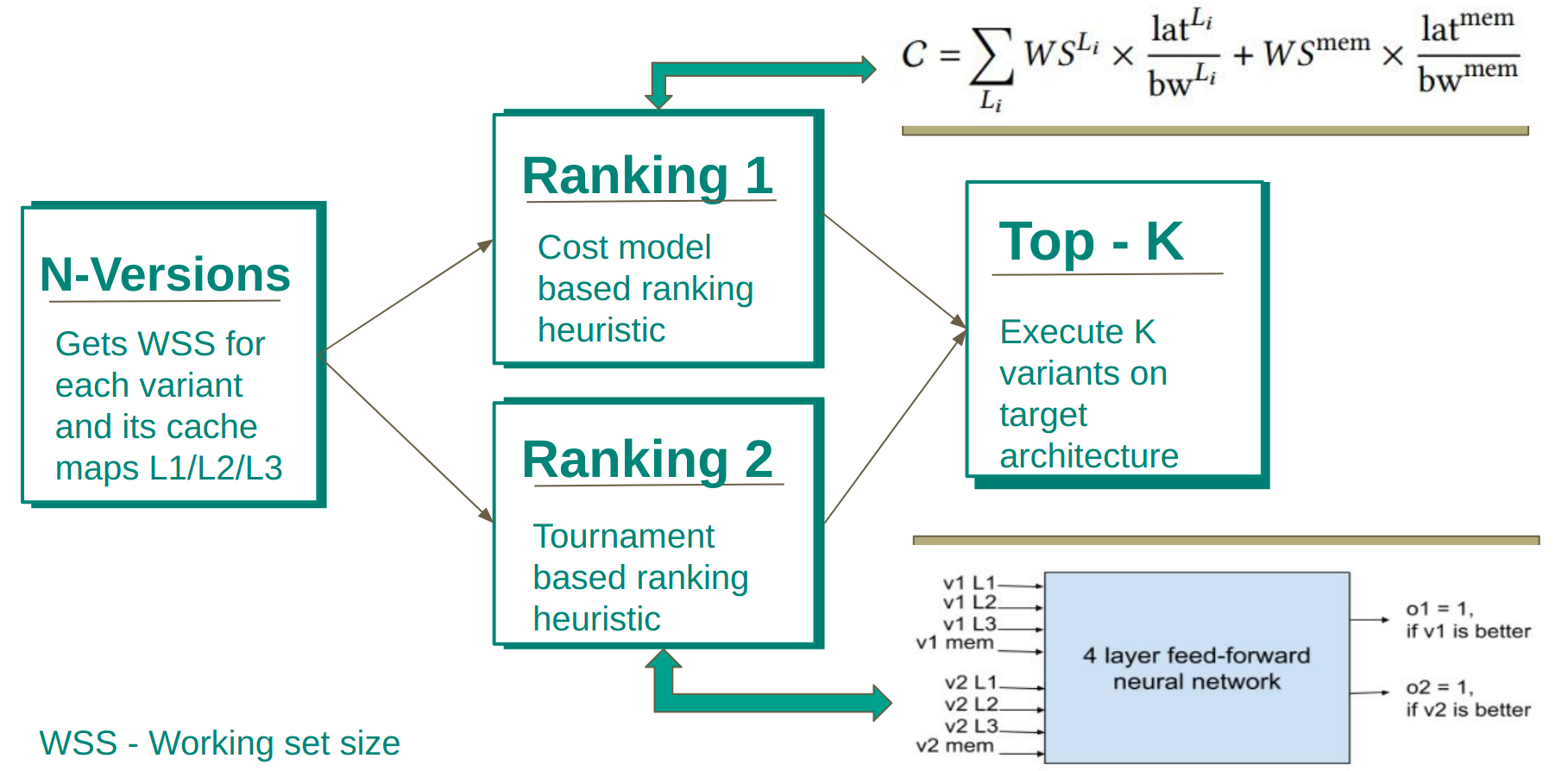
Working set sizes are calculated with the help of data reuse for the n code versions and are mapped to cache. These are passed to our Ranking models. One is a heuristic-based cost modeling ranking system. The other is a Tournament-based ranking system that uses 4 layers of the feed-forward neural network to select the best out of the 2 variants being compared. Finally, every code variant is compared to each other and the variant that gets the maximum wins becomes the best performing variant.
Publications:
1. AI Powered Compiler Techniques for DL Code Optimization
Sanket Tavarageri, Gagandeep Goyal, Sasikanth Avancha, Bharat Kaul, Ramakrishna Upadrasta
Published in arxiv (pre-print)
2. PolyDL: Polyhedral Optimizations for Creation of High-performance DL Primitives
Sanket Tavarageri, Alexander Heinecke, Sasikanth Avancha, Gagandeep Goyal, Ramakrishna Upadrasta, Bharat Kaul
Published in ACM TACO (pre-print) (Talks: HiPEAC’21)
3. PolyScientist: Automatic Loop Transformations Combined with Microkernels for Optimization of Deep Learning Primitives
Sanket Tavarageri, Alexander Heinecke, Sasikanth Avancha, Gagandeep Goyal, Ramakrishna Upadrasta, Bharat Kaul
Published in arxiv (pre-print)
Performance
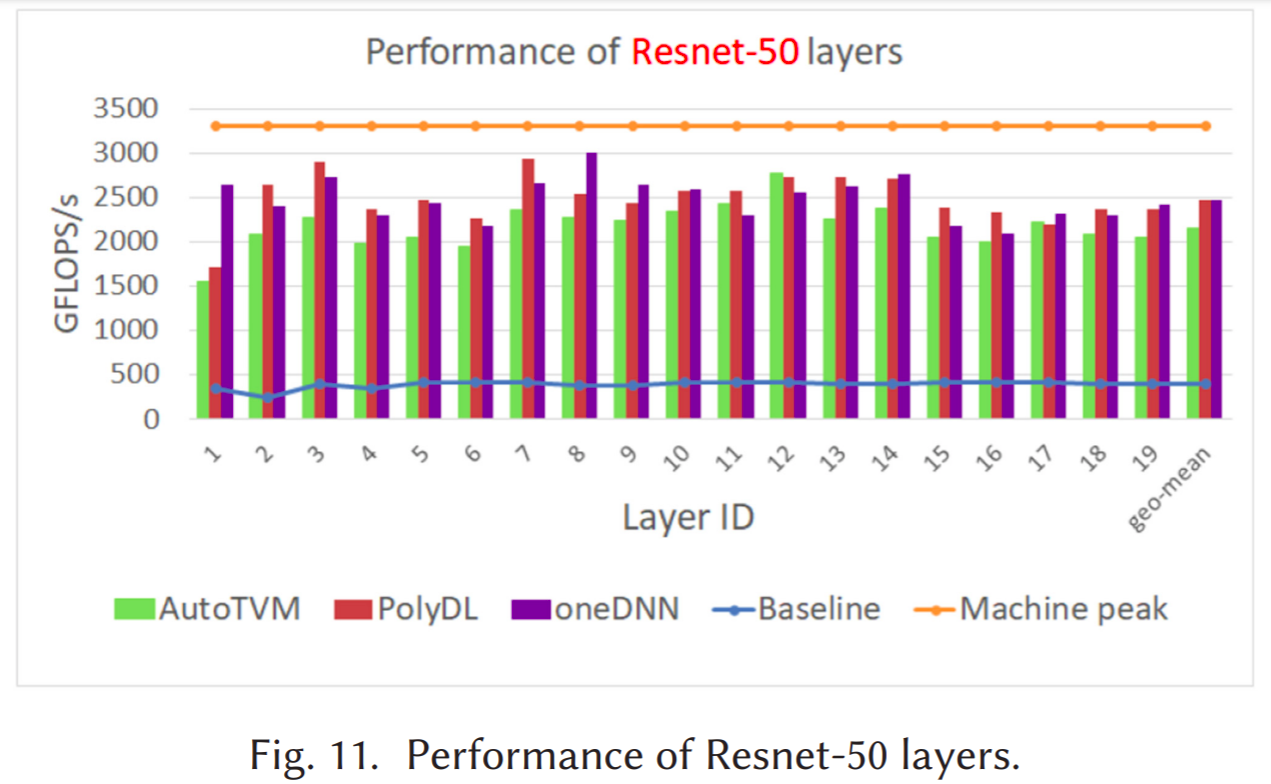
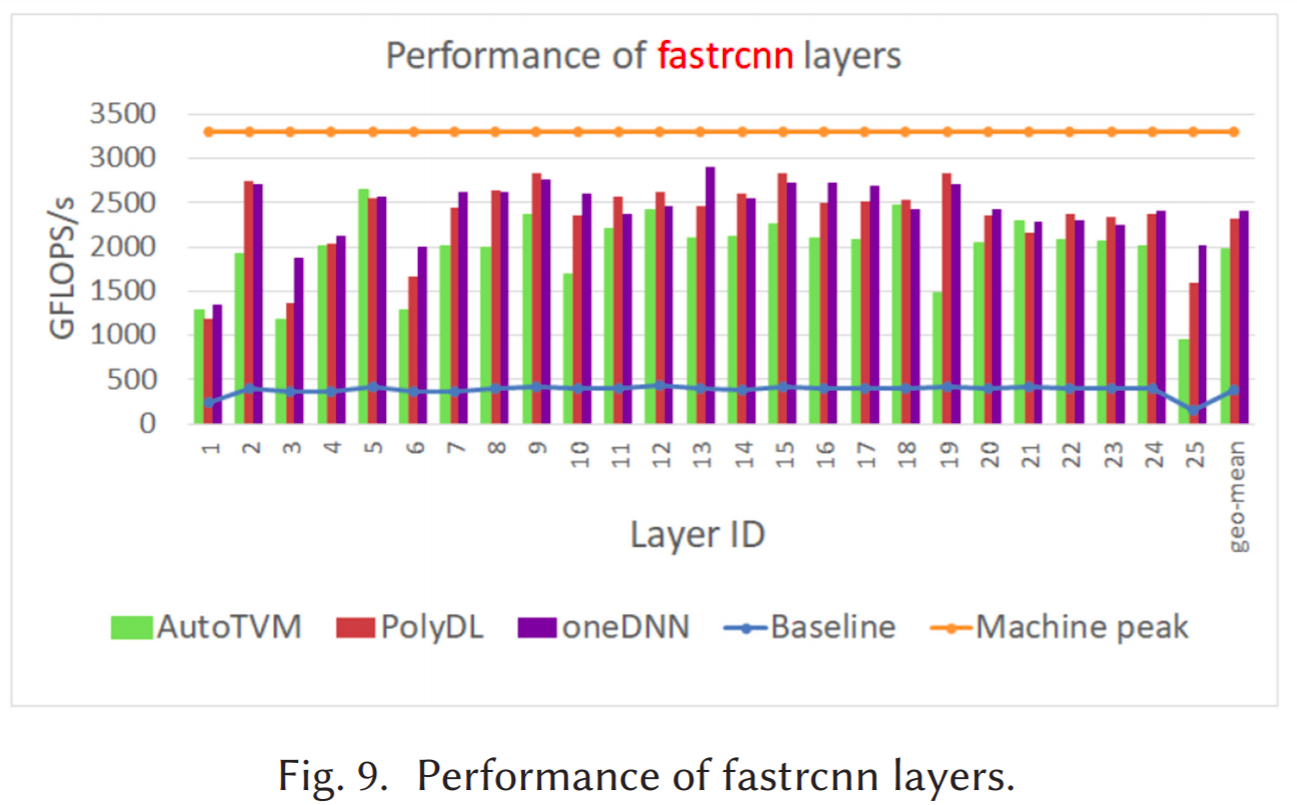
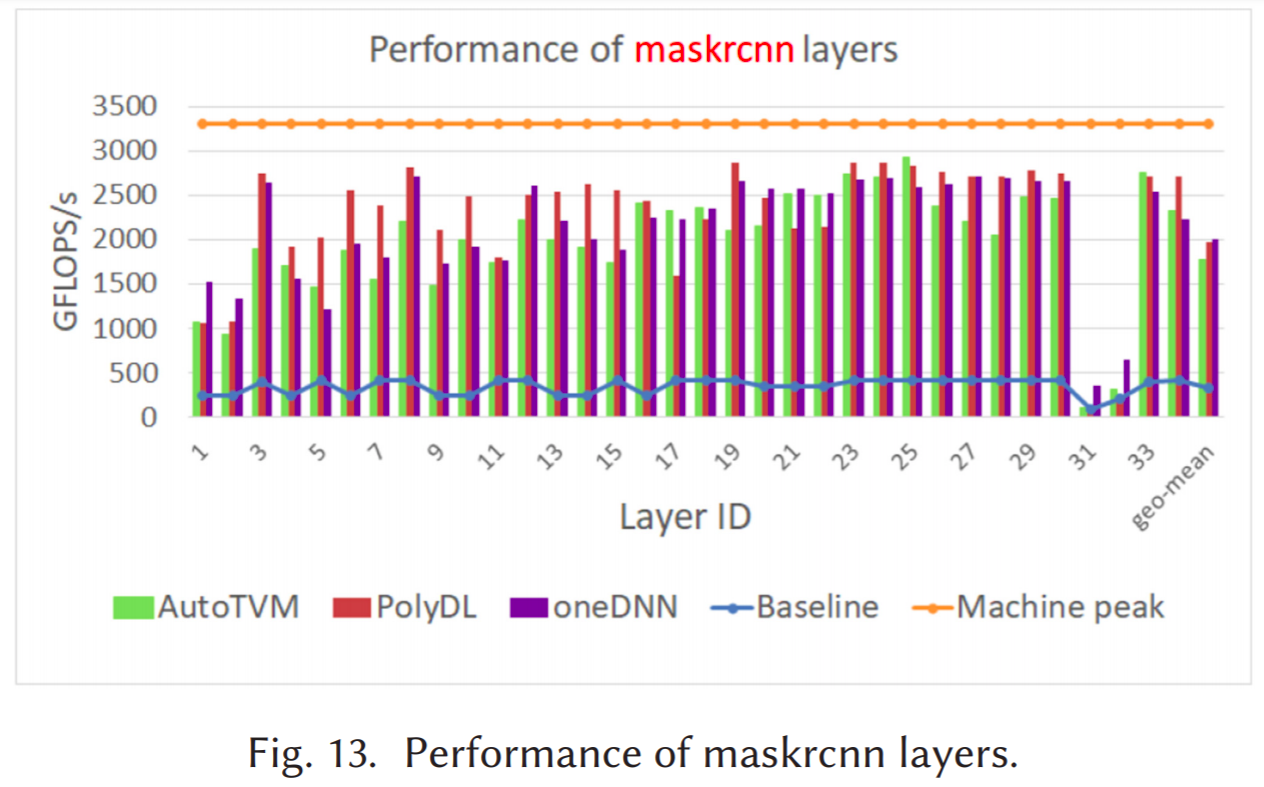
Using our methodology we performed experiments on Convolution and GEMM’s on Intel Xeon Platinum 8280 (a.k.a Cascade Lake) and observed that our performance is similar to the Intel oneDNN library. We also compared the results with AutoTVM (an autotuning system) where we found our performance results were higher. Even AutoTVM takes much longer to derive at a high-performance implementation, where we found that PolyDL is 20 times faster than AutoTVM.
Publications:
1. AI Powered Compiler Techniques for DL Code Optimization
Sanket Tavarageri, Gagandeep Goyal, Sasikanth Avancha, Bharat Kaul, Ramakrishna Upadrasta
Published in arxiv (pre-print)
2. PolyDL: Polyhedral Optimizations for Creation of High-performance DL Primitives
Sanket Tavarageri, Alexander Heinecke, Sasikanth Avancha, Gagandeep Goyal, Ramakrishna Upadrasta, Bharat Kaul
Published in ACM TACO (pre-print) (Talks: HiPEAC’21)
3. PolyScientist: Automatic Loop Transformations Combined with Microkernels for Optimization of Deep Learning Primitives
Sanket Tavarageri, Alexander Heinecke, Sasikanth Avancha, Gagandeep Goyal, Ramakrishna Upadrasta, Bharat Kaul
Published in arxiv (pre-print)
This work was completely superseded by PolyDL.
Funding
This research is funded by the Department of Electronics & Information Technology and the Ministry of Communications & Information Technology, Government of India. This work has been partly supported by the funding received from DST, Govt of India, through the Data Science cluster of the ICPS program (DST/ICPS/CLUSTER/Data Science/2018/General), and an NSM research grant (MeitY/R&D/HPC/2(1)/2014).