LLOV: LLVM OpenMP Verifier
LLOV is a fast, language agnostic, static data race checker for OpenMP programs. It supports OpenMP programs written in C, C++ and FORTRAN. LLOV works on LLVM IR and uses May-Happen-in-Parallel (MHP) analysis and Polyhedral compilation techniques to detect races. It can also verify that a program segment is data race free.
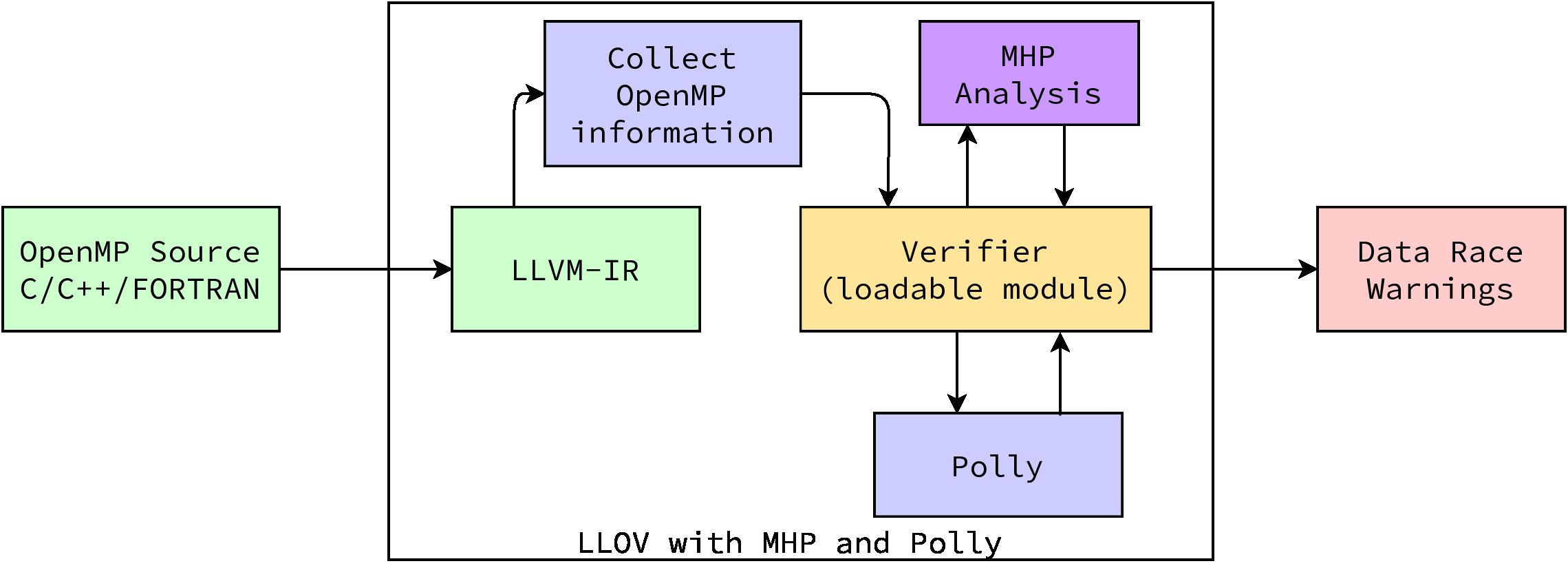
LLOV has two phases, first it performs analysis on LLVM IR, and then performs verification/race-detection using integer sets of ISL and MHP Analysis.
Internals
Race detection using precise Dependence Analysis of Polly:
LLOV models a parallel region as a static control part (SCoP) and computes the dependences.
for ( i = 0; i < m ; i ++) {
#pragma omp parallel for
for ( j = 1; j < n ; j ++) {
b[i][j] = b[i][j -1];
}
}
The above code segment can be represented mathematically using integer sets. We use ISL for integer set operations.
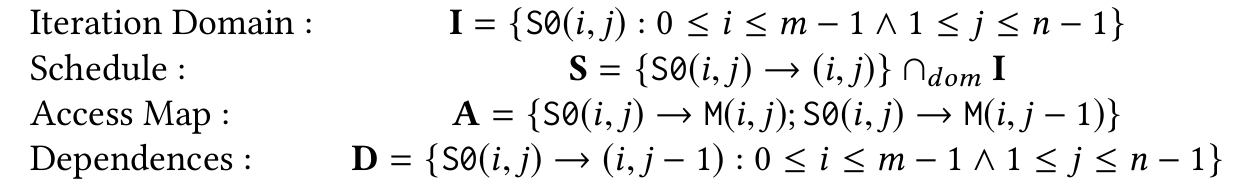
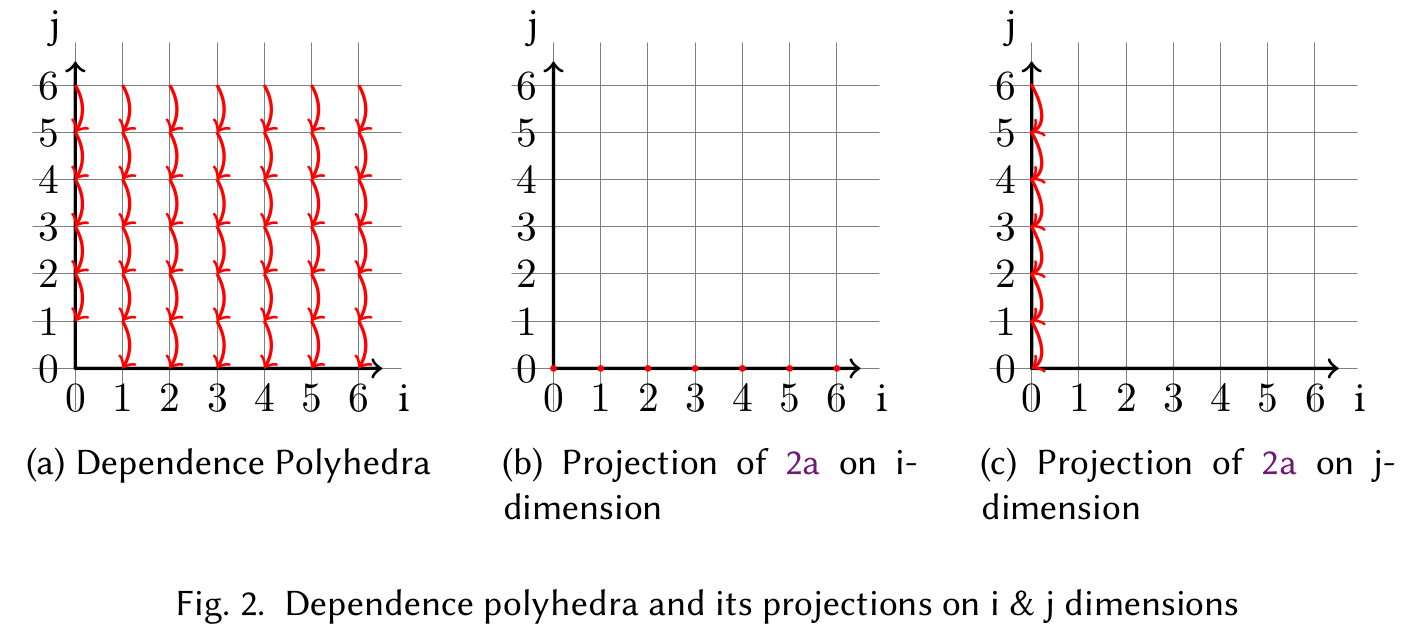
The reduced dependence graph (RDG) for the above code segment is shown in figure 2.a. In order to detect parallel loops, projections of the RDG are taken on each dimension of the loop as shown in figure 2.b and 2.c. The above loop nest is parallel in outer dimension as can be seen from figure 2.b because of zero magnitude projections, whereas the inner loop is not parallel due to non-zero magnitude of the projections. The code segment has a race condition since the dependence across the inner dimension will be violated by this parallelization.
Race detection using MHP Analysis:
In addition to race detection in affine regions that can be exactly modelled by Polly, LLOV performs MHP analysis for regions that cannot be modelled by Polly.
LLOV performs Phase Interval Analysis (PIA) to compute the execution phase of a Basic Block. To perform PIA, LLOV constructs a TaskGraph consisting of the basic blocks, control-flow edges, and call edges. PIA is a forward flow, data-flow analysis in the monotone framework where the domain of analysis is the interval lattice. The phase of execution of a basic block increase 1) upon entering a parallel region, 2) upon encountering a barrier, and 3) upon exiting a parallel region. Each node of the TaskGraph is annotated with the minimum and the maximum phase of execution represented by a closed interval [lb, ub].


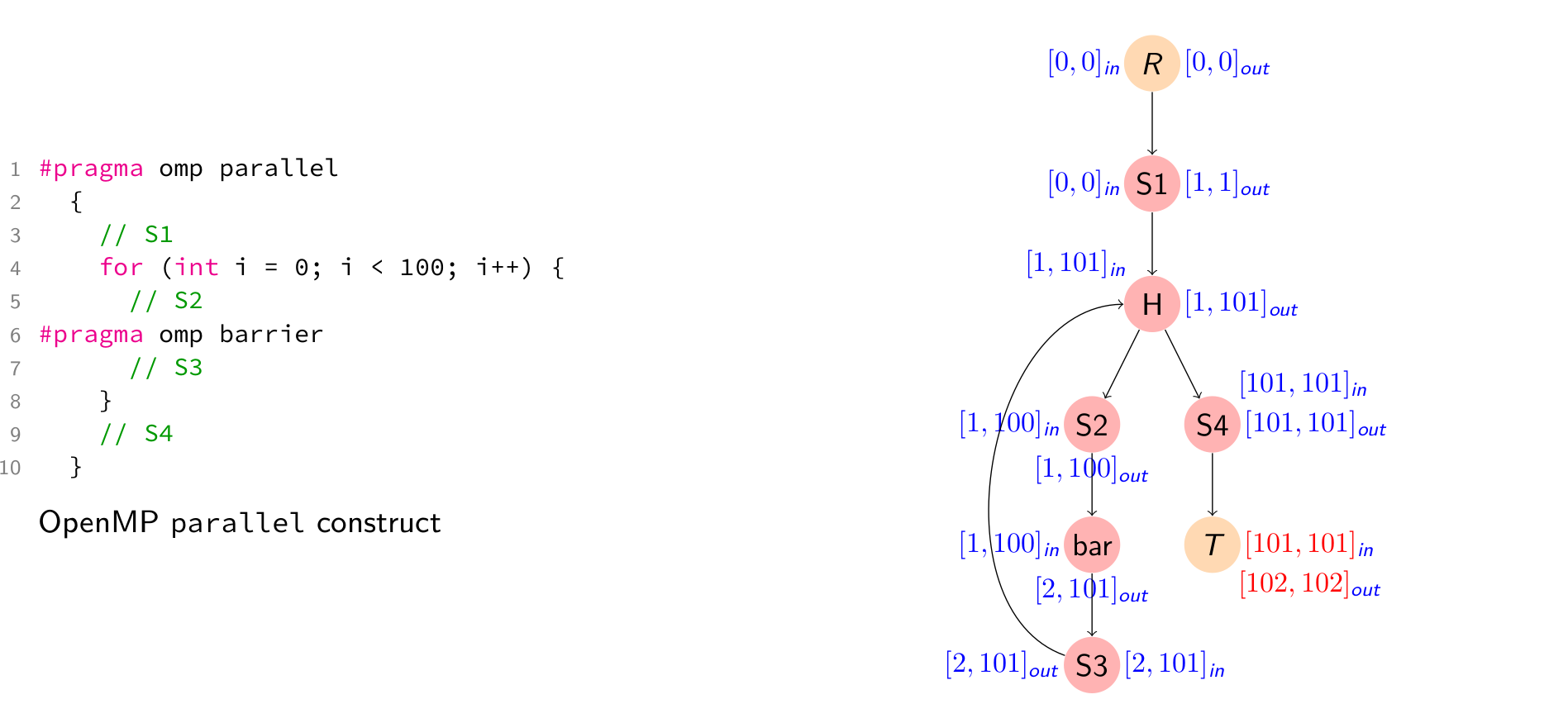
Two nodes in the TaskGraph can run in parallel iff their phase intervals overlap. When the phase intervals of the source and the sink basic blocks of a data dependence overlap, LLOV flags a race signaling a potential data-race condition.

Pragmas supported by LLOV v0.3
| OpenMP Pragma | LLOV-MHP | LLOV | ompVerify | PolyOMP | DRACO | SWORD | Archer v2 | ROMP v2 |
|---|---|---|---|---|---|---|---|---|
| #pragma omp parallel | ||||||||
| #pragma omp for | ||||||||
| #pragma omp parallel for | ||||||||
| #pragma omp critical | ||||||||
| #pragma omp atomic | ||||||||
| #pragma omp master | ||||||||
| #pragma omp single | ||||||||
| #pragma omp simd | ||||||||
| #pragma omp parallel for simd | ||||||||
| #pragma omp parallel sections | ||||||||
| #pragma omp sections | ||||||||
| #pragma omp threadprivate | ||||||||
| #pragma omp ordered | ||||||||
| #pragma omp distribute | ||||||||
| #pragma omp task | ||||||||
| #pragma omp taskgroup | ||||||||
| #pragma omp taskloop | ||||||||
| #pragma omp taskwait | ||||||||
| #pragma omp barrier | ||||||||
| #pragma omp teams | ||||||||
| #pragma omp target |
Performance
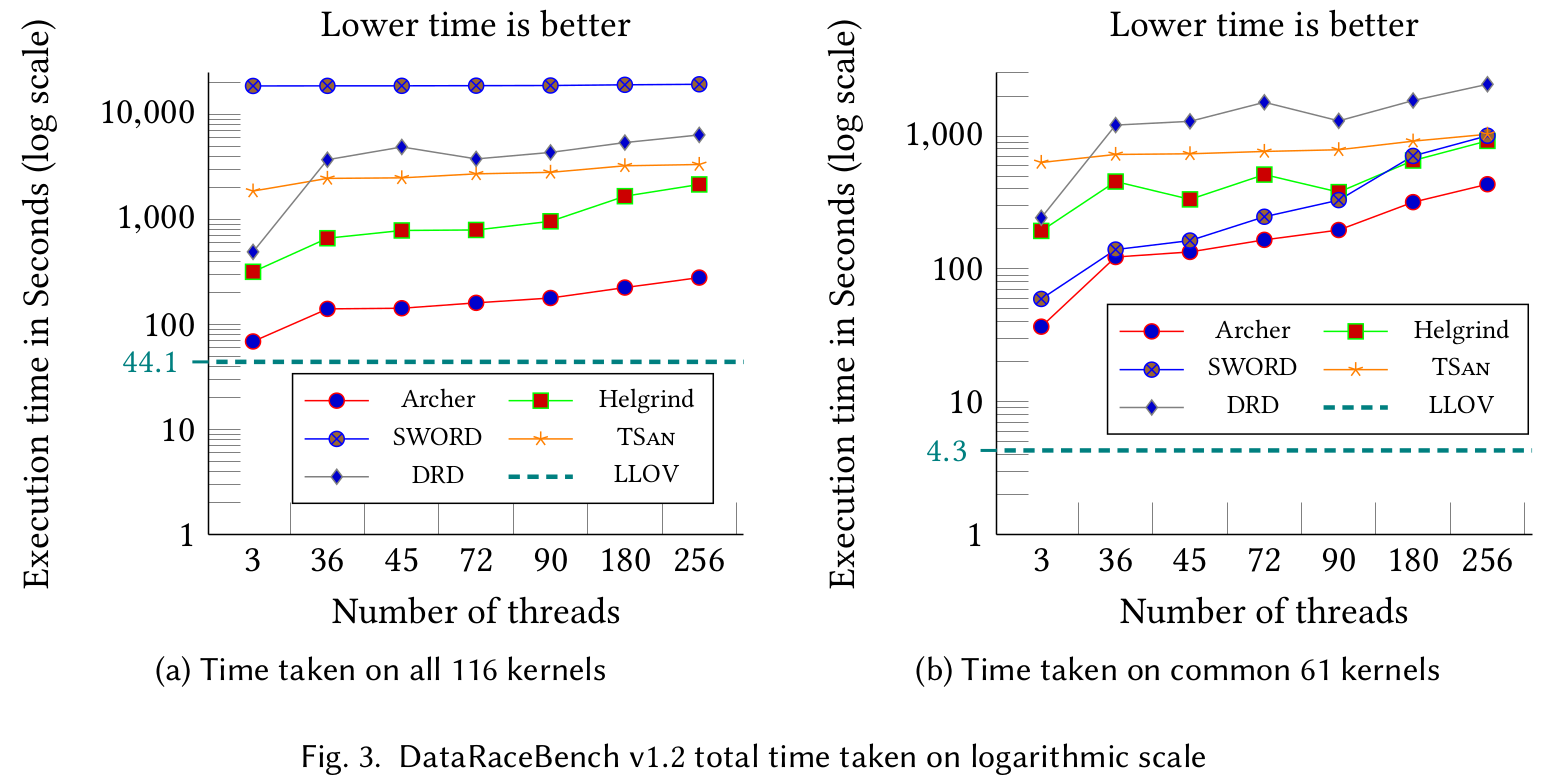
LLOV is orders of magnitude faster than the state-of-the-art race detection tools. It can be seen from the figure 3.a that LLOV takes 44.1 seconds to detect races in all the 116 kernels of DataRaceBench v1.2 on a 72 core Intel machine with 128GB memory. Since the coverage of LLOV and SWORD are not complete, figure 3.b shows time taken to analyze common 61 kernels.
Download LLOV and instructions to run
![]()
![]()
LLOV is available free of cost on our GitHub page.
Publications:
1. OpenMP aware MHP Analysis for Improved Static Data-Race Detection
Utpal Bora, Shraiysh Vaishay, Saurabh Joshi, Ramakrishna Upadrasta
Published in LLVM-HPC’21 (pre-print) (Talks: LLVM-HPC’21)
2. LLOV: A Fast Static Data-Race Checker for OpenMP Programs
Utpal Bora, Santanu Das, Pankaj Kukreja, Saurabh Joshi, Ramakrishna Upadrasta, Sanjay Rajopadhye
Published in ACM TACO (pre-print) (Talks: HiPEAC’21, LLVM-CGO’20)
Funding
This research is funded by the Department of Electronics & Information Technology and the Ministry of Communications & Information Technology, Government of India. This work is partially supported by a Visvesvaraya PhD Scheme under the MEITY, GoI (PhD-MLA/04(02)/2015-16), an NSM research grant (MeitY/R&D/HPC/2(1)/2014), a Visvesvaraya Young Faculty Research Fellowship from MeitY, and a faculty research grant from AMD.
Contact
For any issues, questions, comments or suggestions, feel free to reach out to us at llov-dev@googlegroups.com
Last Modified: June 20, 2024