IR2Vec: LLVM IR based Scalable Program Embeddings
S. VenkataKeerthy, Rohit Aggarwal, Shalini Jain, Maunendra Desarkar, Ramakrishna Upadrasta and Y. N. Srikant
Published in ACM TACO (arXiv) 

IR2Vec is a LLVM IR based framework to generate distributed representations for the source code in an unsupervised manner, which can be used to represent programs as input to solve machine learning tasks that take programs as inputs. It can capture intrinsic characteristics of the program. This is achieved by using the flow analyses information like Use-Def, Reaching Definitions and Live Variable information of the program.
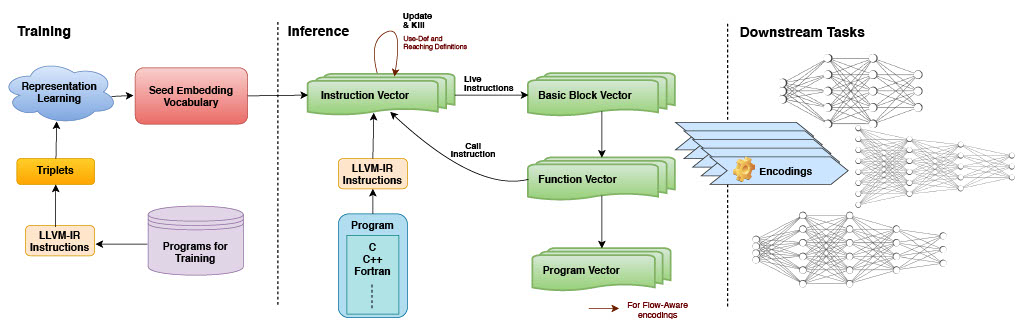
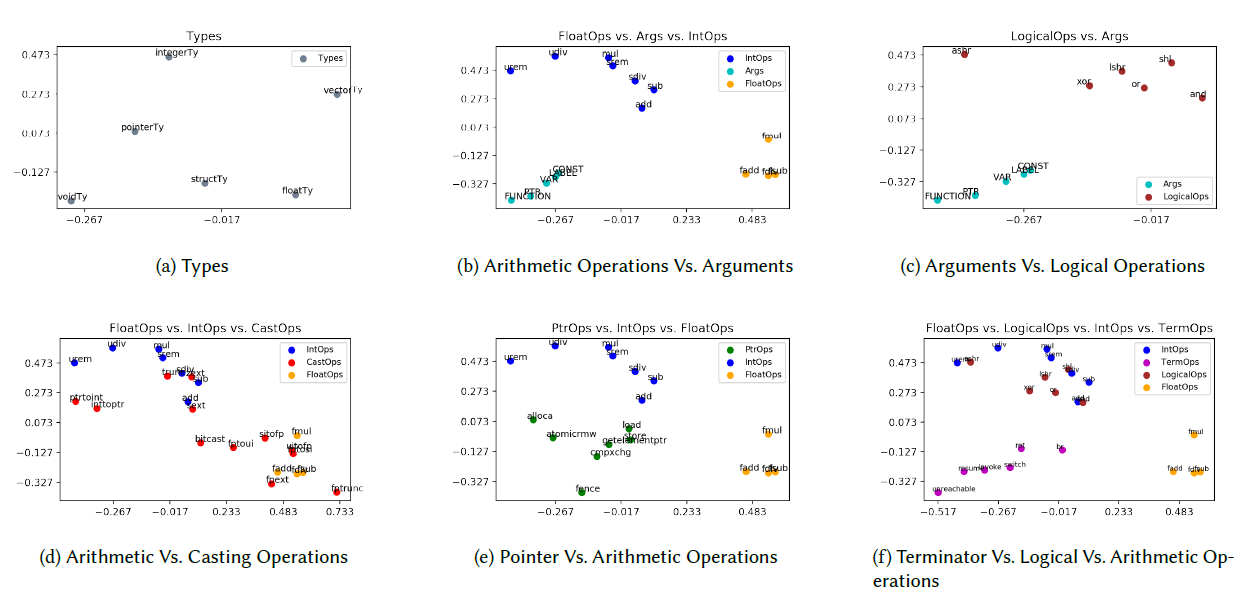
The entities of the IR are modeled as relationships, and their representations are learned to form a seed embedding vocabulary.For this we create a Knowledge Graph by modelling LLVM IR of the program as entities and relations. Then a representation learning algorithm is used to learn the embeddings of these entities. Such embeddings exhibit semantic relationships and form clusters demonstrating them.
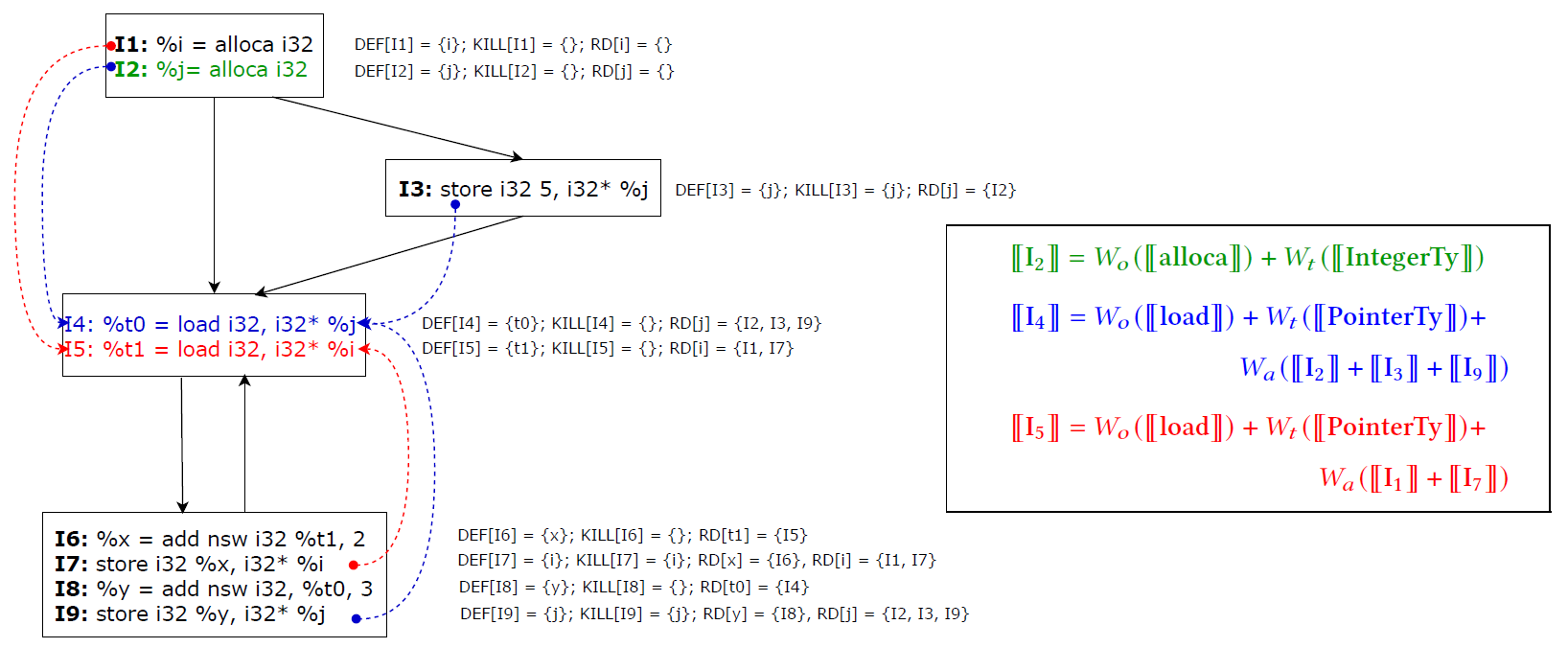
Such seed embeddings are annotated with the flow information to capture semantics of the program and propagated. The vectors to represent programs at various levels (instruction, function, module) can be formed based on the application.
Performance
We demonstrate the effectiveness of the embeddings on two different tasks
- Heterogeneous Device Mapping
- Prediction of Thread Coarsening factor On both of these tasks we achieve better accuracies and speed-ups with very few cases of slow-downs than the state-of-the-art methods.
Other Salient Features
- Compatibility with non-sequential models
- Orders of magnitude of faster training time (Upto 8000x reduction)
- Non data hungry models
- No Out of Vocabulary issues
- Sufficient to expose a training space of O(|opcodes| + |types| + |arguments|)
- when compared to a training space of O(|opcodes| x |types| x |arguments|)
- Maintains very small vocabulary with the embeddings of following entities
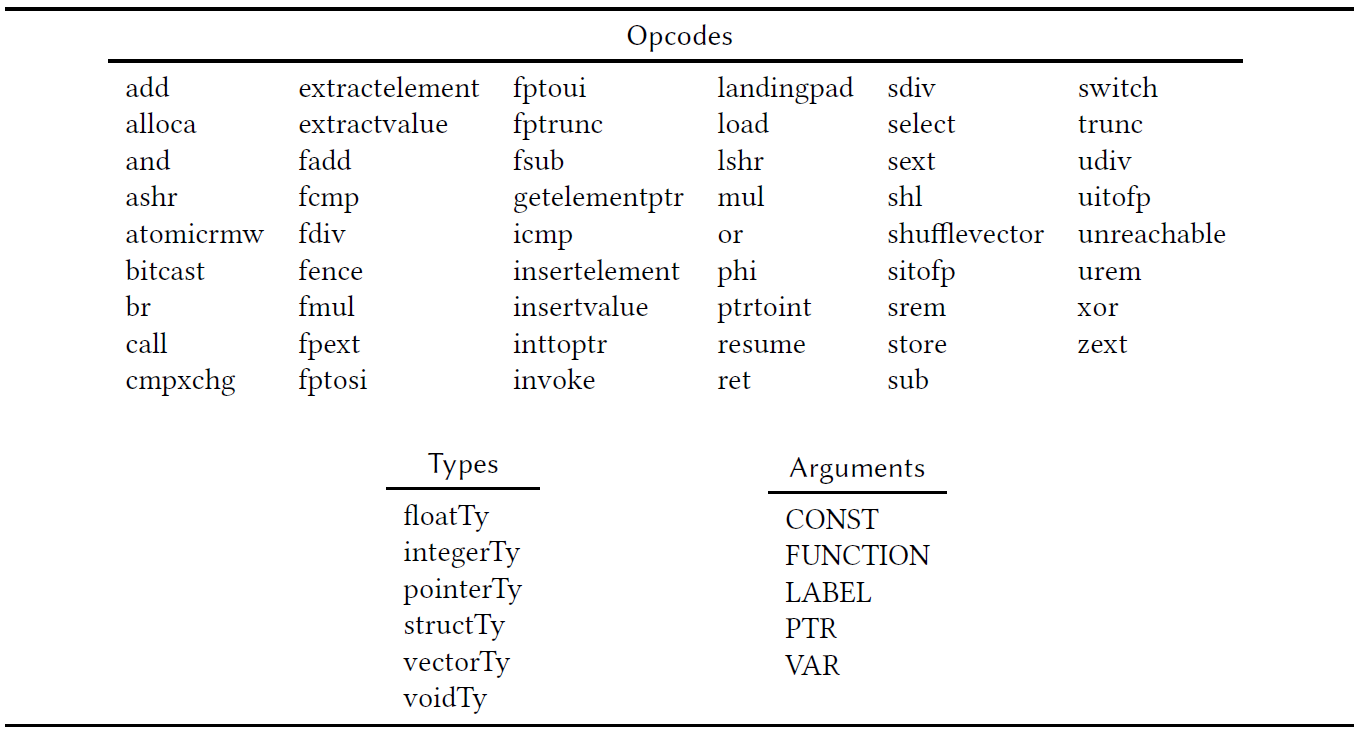
- Sufficient to expose a training space of O(|opcodes| + |types| + |arguments|)
Artifacts
![]()
![]()
Code and other artifacts are available in our GitHub page.
Publications based on IR2Vec
Funding
This research is funded by the Department of Electronics & Information Technology and the Ministry of Communications & Information Technology, Government of India. This work is partially supported by a Visvesvaraya PhD Scheme under the MEITY, GoI (PhD-MLA/04(02)/2015-16), an NSM research grant (MeitY/R&D/HPC/2(1)/2014), a Visvesvaraya Young Faculty Research Fellowship from MeitY, and a faculty research grant from AMD.
What do you think?
If you have any comments or questions, feel free to reach out to us at ir2vec-developers@googlegroups.com
Last Modified: June 20, 2024